Review — CaiT: Going Deeper with Image Transformers
Outperforms ViT, T2T-ViT, DeiT, FixEfficientNet, EfficientNet
Going Deeper with Image Transformers,
CaiT, by Facebook AI, and Sorbonne University
2021 ICCV, Over 100 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Transformer, Vision Transformer, ViT
- CaiT (Class-Attention in Image Transformers) is proposed.
- LayerScale significantly facilitates the convergence and improves the accuracy of image transformers at larger depths.
- Layers with specific class-attention offers a more effective processing of the class embedding.
Outline
- Deeper Image Transformers with LayerScale
- Specializing Layers for Class Attention
- Experimental Results
1. Deeper Image Transformers with LayerScale

- (a) Vision Transformer (ViT): instantiates a particular form of residual architecture: After casting the input image into a set x0 of vectors, the network alternates self-attention layers (SA) with feed-forward networks (FFN), as:

- where η is the layer normalization.
- (b) Fixup [75], ReZero [2] and SkipInit [16]: introduce learnable scalar weighting αl on the output of residual blocks, while removing the pre-normalization and the warmup:

- The empirical observation in this paper is that removing the warmup and the layer normalization is what makes training unstable in Fixup and T-Fixup.
- (c) Both Layer Norm and Learnable Scalar Weighting: When initialized at a small value, this choice does help the convergence when increasing the depth.
- (d) LayerScale: is a per-channel multiplication of the vector produced by each residual block, as opposed to a single scalar.
- The objective is to group the updates of the weights associated with the same output channel. Formally, LayerScale is a multiplication by a diagonal matrix on output of each residual block:

- where the parameters λl,i and λ’l,i are learnable weights.
LayerScale offers more diversity in the optimization than just adjusting the whole layer by a single learnable scalar.
2. Specializing Layers for Class Attention

- (Left) ViT: The class embedding (CLS) is inserted along with the patch embeddings.
- (Middle): Inserting CLS token later improves the performance.
- (Right) CaiT: Further proposes to freeze the patch embeddings when inserting CLS to save compute, so that the last part of the network (typically 2 layers) is fully devoted to summarizing the information to be fed to the linear classifier.
3. Experimental Results
3.1. LayerScale

LayerScale outperforms other weighting variants and baselines.
3.2. Class-Attention Stage
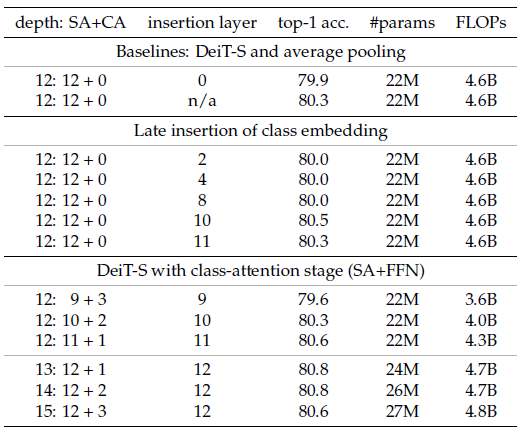
- Using late CLS insertion obtains better results.
With class-attention stage, further improvement is observed.
3.3. Cait Model Variants
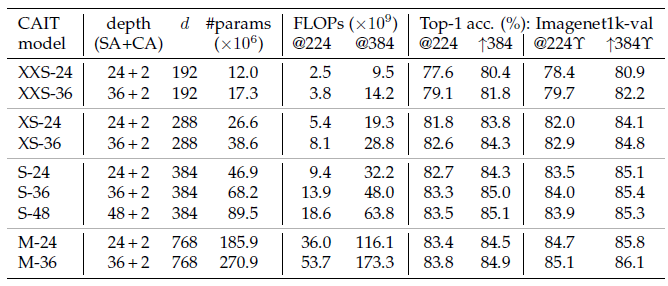
CaiT model variants are constructed from XXS-24 to M-36.
3.4. SOTA Comparison
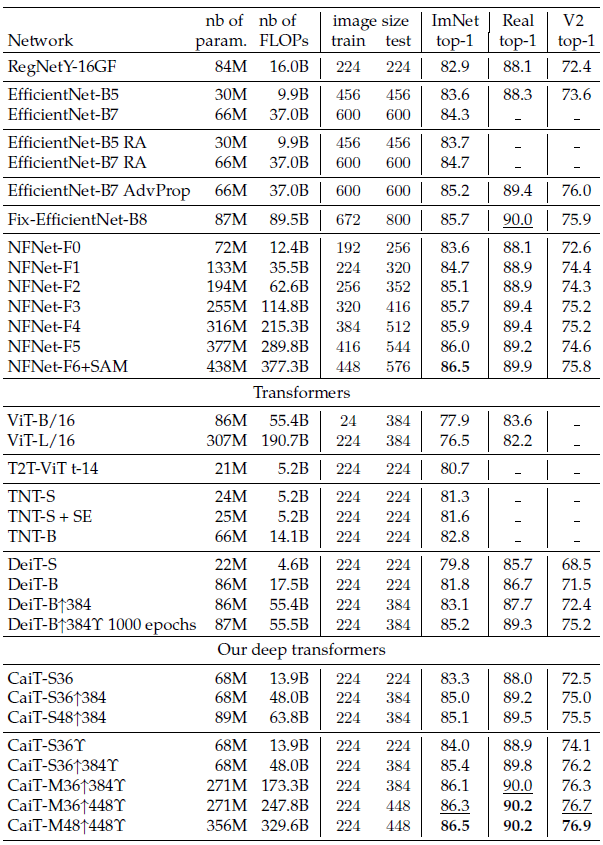
- CaiT can go deeper with better performance.
CaiT obtains higher accuracy compared with others.
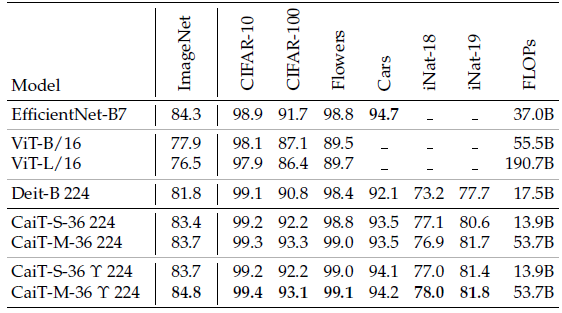
CaiT obtains better performance after fine-tuned to downstream tasks.
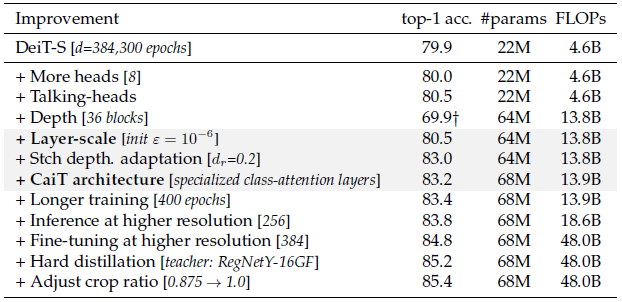
Other than CaiT techniques, techniques from other papers, such as distillation in DeiT, are also used.

Reference
[2021 ICCV] [CaiT]
Going Deeper with Image Transformers
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL] [ciFAIR] [ResNeSt]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT]
