Review — CoAtNet: Marrying Convolution and Attention for All Data Sizes
Combine Strengths of Both Convolutional Networks and Transformers

CoAtNet: Marrying Convolution and Attention for All Data Sizes
CoAtNet, by Google Research, Brain Team
2021 NeurIPS, Over 100 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Transformer, ViT
- Two key insights from CoAtNet:
- Depthwise Convolution and self-Attention can be naturally unified via simple relative attention;
- Vertically stacking convolution layers and attention layers in a principled way is surprisingly effective in improving generalization, capacity and efficiency.
Outline
- Merging Convolution and Self-Attention
- Vertical Layout Design
- SOTA Comparison
- Ablation Studies
1. Merging Convolution and Self-Attention
1.1. Convolution
- Convolution relies on a fixed kernel to gather information from a local receptive field:

- where x is input, y is output, w is weight, and L(i) is the local neighborhood of i.
- In this paper, depthwise convolution, is considered as the MBConv block because both the FFN module in Transformer and MBConv employ the design of “inverted bottleneck”, which first expands the channel size of the input by 4× and later project the the 4×-wide hidden state back to the original channel size to enable residual connection.
1.2. Self-Attention
- Self-attention allows the receptive field to be the entire spatial locations and computes the weights based on the re-normalized pairwise similarity between the pair (xi, xj):

- where G indicates the global spatial space.
1.3. Comparison between Convolution and Self-Attention

- It is much easier for the self-attention to capture complicated relational interactions between different spatial positions, but with a risk of easier overfitting, especially when data is limited, just like ViT.
- Translation equivalence has been found to improve generalization under datasets of limited size. Due to the usage of absolution positional embeddings, standard Transformer (ViT) lacks this property.
- A larger receptive field provides more contextual information, which could lead to higher model capacity. Hence, the global receptive field has been a key motivation to employ self-attention in vision. However, a large receptive field requires significantly more computation. In the case of global attention, the complexity is quadratic w.r.t. spatial size, which has been a fundamental trade-off in applying self-attention models.
1.4. Proposed Merging Convolution and Self-Attention
- A straightforward idea that could achieve this is simply to sum a global static convolution kernel with the adaptive attention matrix, either after or before the Softmax normalization, i.e.:

- In this case, the attention weight Ai,j is decided jointly by the wi-j of translation equivariance and the input-adaptive xi, xj.
- Consider not to blow up the number of parameters, the notation of wi-j is reloaded as a scalar, resulting in minimum additional cost.
The proposed CoAtNet uses the pre-normalization relative attention version.
2. Vertical Layout Design
2.1. 5 Variants
- Different stackings are tried.
- ViTREL: When the ViT Stem is used, L Transformer blocks are directly stacked with relative attention.
- When the multi-stage layout is used, a network of 5 stages (S0, S1, S2, S3 & S4), is constructed.
- The first stage S0 is a simple 2-layer convolutional Stem and S1 always employs MBConv blocks with squeeze-excitation (SE), as the spatial size is too large for global attention.
- Starting from S2 through S4, we consider either the MBConv or the Transformer block, with a constraint that convolution stages must appear before Transformer stages. The constraint is based on the prior that convolution is better at processing local patterns that are more common in early stages.
- This leads to 4 variants with increasingly more Transformer stages, C-C-C-C, C-C-C-T, C-C-T-T and C-T-T-T, where C and T denote Convolution and Transformer respectively.
2.2. Generalization Capability
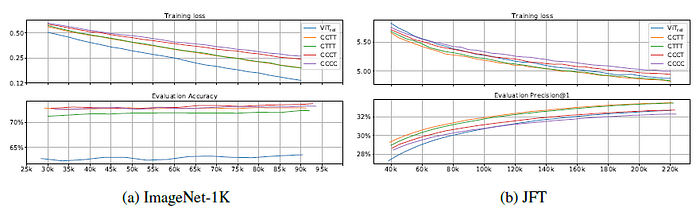
- From the ImageNet-1K results, a key observation is that, in terms of generalization capability (i.e., gap between train and evaluation metrics):
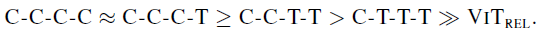
- Particularly, ViTREL is significantly worse than variants by a large margin.
- Among the multi-stage variants, the overall trend is that the more convolution stages the model has, the smaller the generalization gap is.
2.3. Model Capacity
- As for model capacity, from the JFT comparison, both the train and evaluation metrics at the end of the training suggest the following ranking:
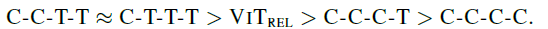
- On one hand, while initially worse, ViTREL ultimately catch up with the two variants with more MBConv stages, indicating the capacity advantage of Transformer blocks.
- On the other hand, both C-C-T-T and C-T-T-T clearly outperforming ViTREL.
2.4. Transferability

- The above two JFT pre-trained models are fine-tuned on ImageNet-1K for 30 epochs and compare their transfer performances.
- It turns out that C-C-T-T achieves a clearly better transfer accuracy than C-T-T-T, despite the same pre-training performance
Taking generalization, model capacity, transferability and efficiency into consideration, C-C-T-T multi-stage layout is adopted for CoAtNet.
3. Experimental Results
3.1. CoAtNet

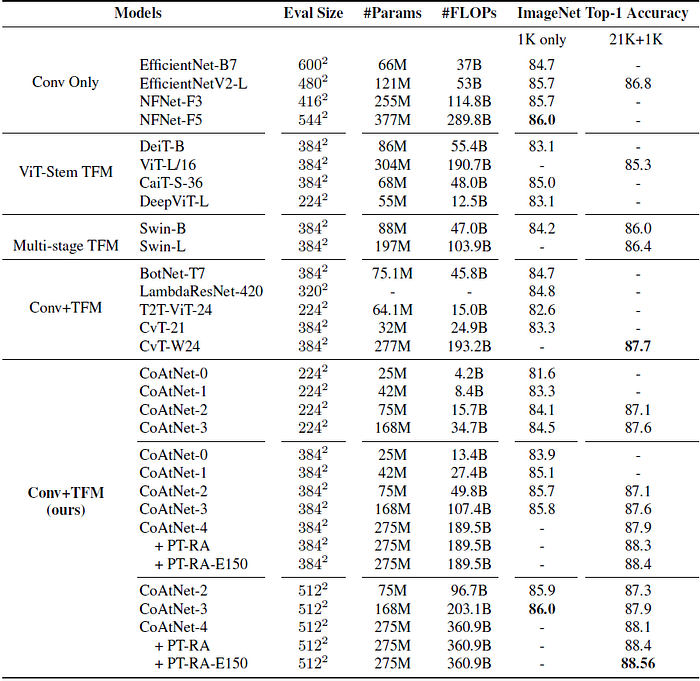
- A family of CoAtNet is designed for different model sizes.
3.2. ImageNet-1K & ImageNet-21K
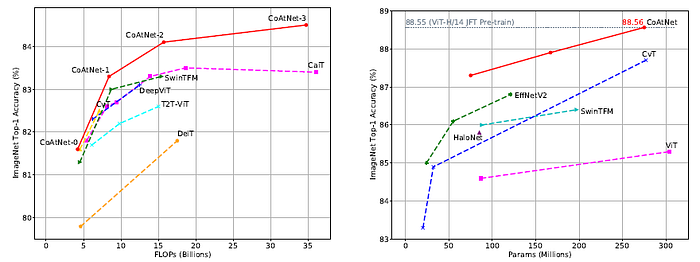
3.2.1. ImageNet-1K
- The proposed CoAtNet models not only outperform ViT variants such as DeiT, CaiT, T2T-ViT, Swin Transformer and CvT, but also match the best convolution-only architectures, i.e., EfficientNetV2 and NFNets.
As we can see, CoAtNet scales much better than previous model with attention modules.
3.2.2. ImageNet-21K
- Notably, the best CoAtNet variant achieves a top-1 accuracy of 88.56%, matching the ViTH/14 performance of 88.55%, which requires pre-training the 2.3× larger ViT model on a 23× larger proprietary weakly labeled dataset (JFT) for 2.2× more steps.
This marks a dramatic improvement in both data efficiency and computation efficiency.
3.3. JFT
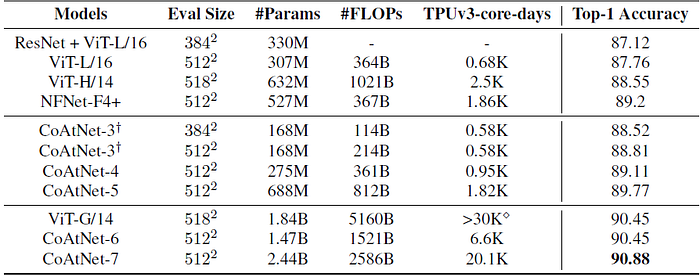
- Encouragingly, CoAtNet-4 can almost match the best previous performance with JFT-300M set by NFNet-F4+, while being 2× more efficient in terms of both TPU training time and parameter count.
- When the model is scaled up to consume similar training resource as NFNet-F4+, CoAtNet-5 reaches 89.77% on top-1 accuracy, outperforming previous results under comparable settings.
- With over 4× less computation than ViT-G/14, CoAtNet-6 matches the performance of ViT-G/14 of 90.45%, and with 1.5× less computation, CoAtNet-7 achieves 89.77% on top-1 accuracy 90.88%, achieving the new state-of-the-art performance.
4. Ablation Studies

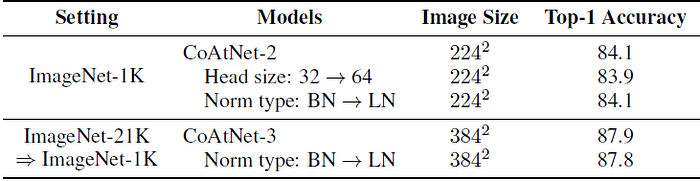
- When only the ImageNet-1K is used, relative attention clearly outperforms the standard attention, indicating a better generalization.
- In addition, under the ImageNet-21K transfer setting, the relative attention variant achieves a substantially better transfer accuracy, despite their very close pre-training performances.
This suggests the main advantage of relative attention in visual processing is not in higher capacity but in better generalization.
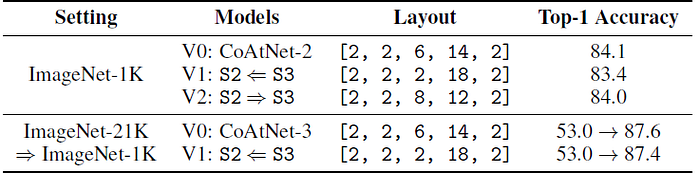
- A question to ask is how to split the computation between S2 (MBConv) and S3 (Transformer) to achieve a good performance.
- If the total number of blocks in S2 and S3 are fixed and the number in each stage is varied, V0 is a sweet spot between V1 and V2.
- The sweet spot also holds in the transfer setting that the transfer accuracy of V1 clearly falls behind V0.
Reference
[2021 NeurIPS] [CoAtNet]
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Image Classification
1989 … 2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1] [CvT] [HaloNet] [TNT] [CoAtNet]
