Review — HaloNet: Scaling Local Self-Attention for Parameter Efficient Visual Backbones
HaloNet, Localized Window for Self-Attention
Scaling Local Self-Attention for Parameter Efficient Visual Backbones
HaloNet, by Google Research, and UC Berkeley
2021 CVPR, Over 80 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Self-Attention
- A new self-attention model family, HaloNets, is developed:
- A strided self-attention layer, a natural extension of strided convolutions, is developed.
- To deal with the computational cost in larger resolutions where global attention is infeasible, the fairly general principle of local processing is followed, a spatially restricted forms of self-attention is formed.
Outline
- Convolution, Self-Attention, and SASA
- HaloNet: Model Architecture
- Experimental Results
1. Convolution, Self-Attention, and SASA
- A general form of a local 2D pooling function that computes an output at location (i, j):

- where f(i, j, a, b) is a function that returns a weight matrix W.
1.1. Convolution
- When it is convolution:

1.2. Self-Attention
- For self-attention, WQ, WK, and WV are learned linear transformations that are shared across all spatial locations, and respectively produce queries, keys, and values when used to transform x:

1.3. SASA
- In SASA, self-attention is within the local window N(i, j), which is a k×k window centered around (i, j), just like a convolution.
1.4. Computational Cost
Thus, for SASA, increasing k does not not impact the number of parameters of the layer significantly.
For convolution, the number of parameters in a convolution layer scales quadratically with k (e.g.: a 5×5 convolution has 25/9 times the parameters of a 3×3 convolution).
On the other hand, the computational cost of self-attention grows quadratically with k, preventing the use of very large values for k.
2. HaloNet: Model Architecture

- A compromise solution can be achieved by leveraging the idea that neighboring pixels share most of their neighborhood.
- The FLOPs can be controlled by varying the number of pixels that form a block. We name this strategy blocked local self-attention.
- The two extremes discussed above are a special case of blocked local self-attention. Global attention corresponds to setting the block size to be the entire spatial extent, while the per-pixel extraction corresponds to setting the block size to be 1.
2.1. Blocked Local Self-Attention
- For an image with height H=4, width W=4, and c channels with stride 1. Blocking chops up the image into a H/b, W/b tensor of non-overlapping (b, b) blocks.
- Each block behaves as a group of query pixels and a haloing operation combines a band of h pixels around them (with padding at boundaries) to obtain the corresponding shared neighborhood block of shape (H/b, W/b, b+2h, b+2h, c) from which the keys and values are computed.
- H/b×W/b attention operations then run in parallel for each of the query blocks and their corresponding neighborhoods.
- Another perspective is that blocked local self-attention is only translational equivariant to shifts of size b. SASA used the same blocking strategy, but setting h=⌊k/2⌋.

- The above table compares different attention approaches.

- Another difference with SASA is the HaloNet’s implementation of downsampling. HaloNet replaces attention followed by post-attention strided average pooling, by a single strided attention layer that subsamples queries similar to strided convolutions.
- This change does not impact accuracy while also reducing the FLOPs 4× in the downsampling layers.
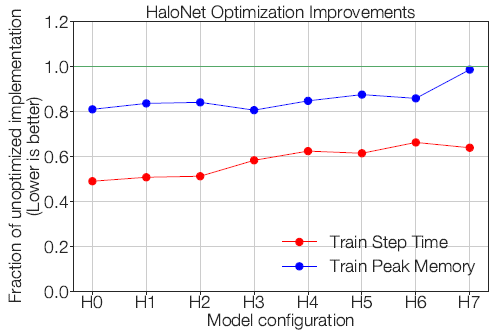
- Taken together, the speedups produced by these improvements are significant as seen above, with up to 2× improvements in step time.
2.2. HaloNet Variants

- The deeper layers of multiscale architectures, smaller spatial dimensions and larger channels. HaloNet also takes advantage of this.
- HaloNet leverages the structure of ResNets that stack multiple residual bottleneck blocks together, as tabulated above. HaloNet uses a few minor modifications from ResNets:
- Adding a final 1×1 convolution before the global average pooling for larger models, following EfficientNet.
- Modifying the bottleneck block width factor, which is traditionally fixed at 4.
- Modifying the output width multiplier of the spatial operation, which is traditionally fixed at 1.
- Changing the number of blocks in the third stage from 4 to 3 for computational reasons because attention is more expensive in the higher resolution layers.
- The number of heads is fixed for each of the four stages to (4, 8, 8, 8) because heads are more expensive at higher resolutions.
- To summarize, the scaling dimensions in HaloNet are: image size s, query block size b, halo size h, attention output width multiplier rv, bottleneck output width multiplier rb, number of bottleneck blocks in the third group l3, and final 1×1 conv width df. The attention neighborhoods range from 14×14 (b=8, h=3) to 18×18 (b=14, h=2).
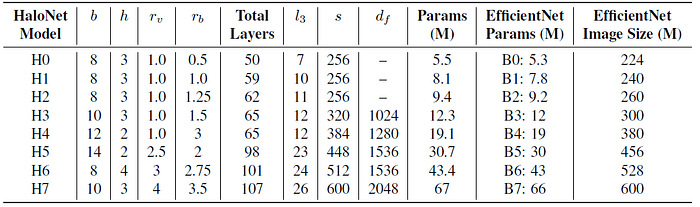
- Finally, the HaloNet variants from H0 to H7 are established.
3. Experimental Results
3.1. Comparison with EfficientNet

HaloNets perform at par or slightly better than EfficientNet models for the same parameters, outperforming other model families.
- The proposed best model, H7, achieves 84.9% top-1 ImageNet validation accuracy and 74.7% top-1 accuracy on ImageNet-V2.
To the best of authors’ knowledge, these results are the first to show that self-attention based models for vision perform on par with the SOTA for image classification when trained on imageNet from scratch.
3.2. Transfer of Convolutional Components to Self-Attention
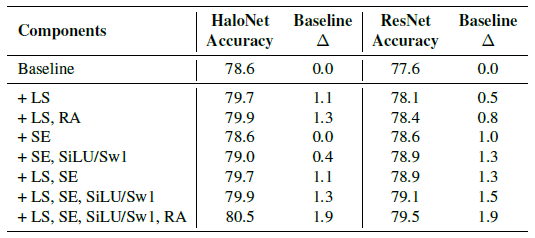
- Starting from a baseline model, adding label smoothing (LS) in Inception-v3, RandAugment (RA), Squeeze-and-Excitation (SE), and SiLU/Swish-1 (SiLU/Sw1).
Surprisingly, regularizations of the same strength improve HaloNet accuracies significantly more than ResNet, despite HaloNet having around 30% fewer parameters than ResNet.
- Label smoothing in Inception-v3, SiLU/Swish-1, and RandAugment are used in the proposed HaloNet H0-H7 models.
3.3. Increasing Image Sizes Improve Accuracies
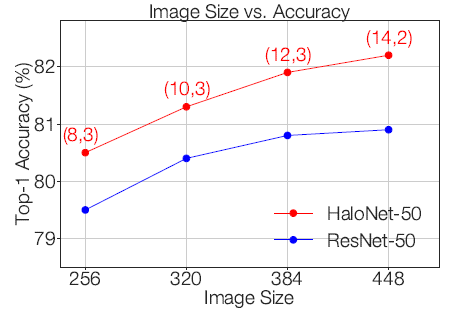
HaloNet consistently improves when using larger images.
3.4. Relaxing Translational Equivariance
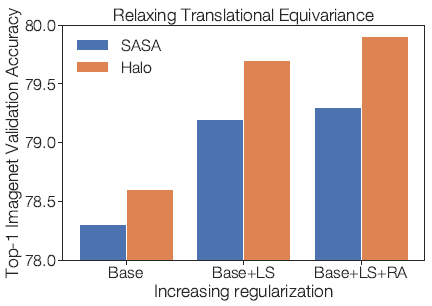
HaloNet-50 with b=8, and h=3 achieves better accuracies using the same block and halo to achieve 7×7 neighborhoods with attention masks and the gap widens with more regularizations.
3.5. Convolution-Attention Hybrids Improve the Speed-Accuracy Tradeoff
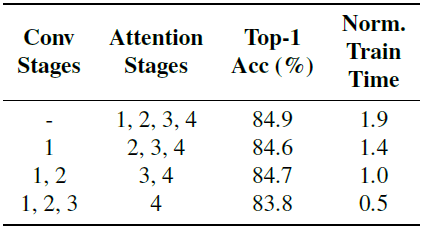
Splitting the allocation between convolutions (in stages 1–2) and attention (in stages 3–4) minimally detriments predictive accuracy while significantly improving training and inference step times.
3.6. Window and Halo Size
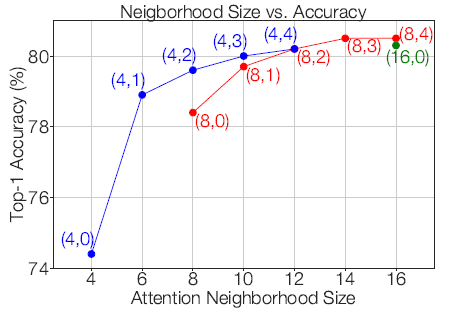
Accuracy consistently improves as the window size increases. In particular, doubling the window size from 6×6 to 12×12 produces a 1.3% accuracy gain.
3.7. Transfer from ImageNet21k
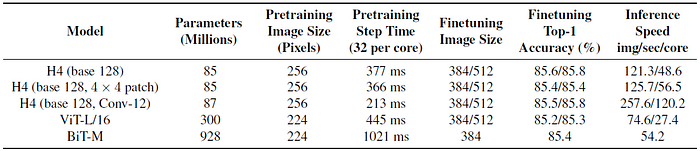
Wider H4 and hybrid-H4 models achieves better accuracy than the Vision Transformer, ViT, and a 4× wide ResNet-152 from BiT and are also faster at inference on larger images.
3.8. Detection and Instance Segmentation
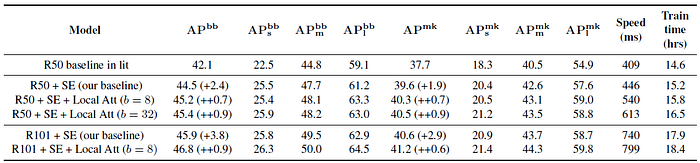
- Mask R-CNN framework is used.
The attention variants achieve at least 0.7 mAP gains on bounding box detection and at least 0.6 mAP gains on instance segmentation on top of our stronger baselines.
3.9. Pure Attention Based HaloNet is Slower
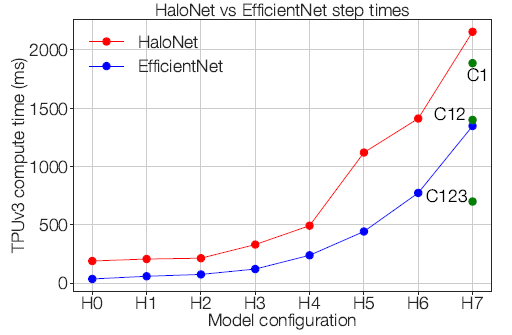
- However, pure self-attention based HaloNets are currently slower to train than the corresponding EfficientNets and require further optimizations for large batch training.
Reference
[2021 CVPR] [HaloNet]
Scaling Local Self-Attention for Parameter Efficient Visual Backbones
Image Classification
1989 … 2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1] [CvT] [HaloNet]
