Review — ResNet-RS: Re-Scaling ResNet
With Better Rescaling for ResNet, Outperforms EfficientNet

Revisiting ResNets: Improved Training and Scaling Strategies
ResNet-RS, by Google Brain, and UC Berkeley
2021 NeurIPS, Over 50 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Residual Network, ResNet
- Two new scaling strategies are offered:
- Scale model depth in regimes where overfitting can occur (width scaling is preferable otherwise).
- Increase image resolution more slowly than previously recommended.
Outline
- Improved Training Methods
- Improved Scaling Strategies
- Experimental Results
1. Improved Training Methods
- Since the original ResNet uses old training recipes, before introducing new scaling strategies, training methods are improved first.

1.1. Training, Regularization and Architecture Improvements (Left)
- The baseline ResNet-200 gets 79.0% top-1 accuracy.
- Its performance is improved to 82.2% (+3.2%) through improved training methods alone without any architectural changes.
- Adding two common and simple architectural changes (Squeeze-and-Excitation in SENet, and ResNet-D in Bags of Tricks) further boosts the performance to 83.4%.
Training methods alone cause 3/4 of the total improvement.
1.2. Importance of Decreasing Weight Decay When Combining Regularization Methods (Right)
- The amount of weight decay is decreased with the use of other regularization methods, in order for better performance.
The intuition is that since weight decay acts as a regularizer, its value must be decreased in order to not overly regularize the model when combining many techniques.
2. Improved Scaling Strategies
- An extensive search is performed on ImageNet over width multipliers in [0.25,0.5,1.0,1.5,2.0], depths of [26,50,101,200,300,350,400] and resolutions of [128,160,224,320,448], using 350 epochs.
2.1. Strategy #1 — Depth Scaling in Regimes Where Overfitting Can Occur

2.1.1. Right: Depth scaling outperforms width scaling for longer epoch regimes
- Scaling the width is subject to overfitting and sometimes hurts performance even with increased regularization. This is due to the larger increase in parameters when scaling the width.
2.1.2. Left & Middle: Width scaling outperforms depth scaling for shorter epoch regimes
- In contrast, width scaling is better when only training for 10 epochs (Left). For 100 epochs (Middle), the best performing scaling strategy varies between depth scaling and width scaling, depending
2.2 Strategy #2 — Slow Image Resolution Scaling
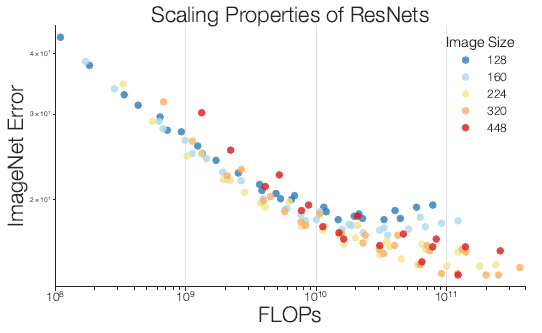
- For the smaller models, we observe an overall power law trend between error and FLOPs. However, the trend breaks for larger model sizes.
- Larger image resolutions yield diminishing returns.
- Therefore authors propose to increase the image resolution more gradually than previous works. (600 for EfficientNet-B7, 800 for EfficientNet-L2, 400+ for ResNeSt and TResNet.)
3. Experimental Results
3.1. ResNet-RS on a Speed-Accuracy Basis


ResNet-RS match EfficientNets’ performance while being 1.7×-2.7× faster on TPUs (2.1×-3.3× faster on GPUs).
- These speed-ups are superior to those obtained by TResNet and ResNeSt.
3.2. Semi-Supervised Learning with ResNet-RS

- ResNets-RS is trained on the combination of 1.3M labeled ImageNet images and 130M pseudo-labeled images, in a similar fashion to Noisy Student.
- The pseudo labels are generated from an EfficientNet-L2.
ResNet-RS models are very strong in the semi-supervised learning setup as well, achieving a strong 86.2% top-1 ImageNet accuracy while being 4.7× faster on TPU (5.5× on GPU) than the corresponding EfficientNet.
3.3. Transfer Learning to Downstream Tasks with ResNet-RS

- The improved training strategies (RS) greatly outperforms the baseline supervised training, which highlights the importance of using improved supervised training techniques when comparing to self-supervised learning algorithms.
3.4 Revised 3D ResNet for Video Classification
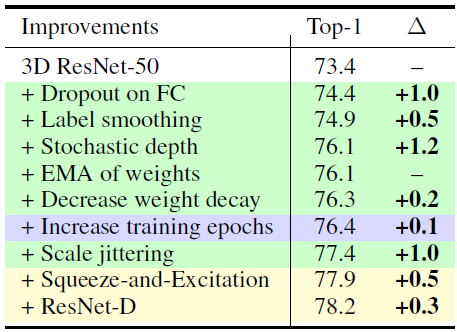
- The training strategies extend to video classification, yielding a combined improvement from 73.4% to 77.4% (+4.0%).
- The ResNet-D and Squeeze-and-Excitation architectural changes further improve the performance to 78.2% (+0.8%).
Most of the improvement can be obtained without architectural changes.
- (There are also many results in the appendix.)
- Recently, there are many works revisited and improved ResNet a lot such as ResNet Strikes Back.
Reference
[2021 NeurIPS] [ResNet-RS]
Revisiting ResNets: Improved Training and Scaling Strategies
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL] [ciFAIR] [ResNeSt]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS]
