Brief Review — EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
Going Faster with Vision Transformers

EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
EfficientViT, by The Chinese University of Hong Kong, and Microsoft Research
2023 CVPR, Over 220 Citations (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++] [FastViT] [EfficientFormerV2] [MobileViTv2] [ConvNeXt V2] [SwiftFormer] [OpenCLIP] 2024 [FasterViT] [CAS-ViT] [TinySaver] [RDNet]
==== My Other Paper Readings Are Also Over Here ====
- The speed of existing transformer models is commonly bounded by memory inefficient operations especially the tensor reshaping and element-wise functions in MHSA, thus, EfficientViT is proposed.
- A new building block with a sandwich layout is proposed, i.e., using a single memory-bound MHSA between efficient FFN layers, which improves memory efficiency while enhancing channel communication.
- A cascaded group attention (CGA) module is proposed, by feeding attention heads with different splits of the full feature, which not only saves computation cost but also improves attention diversity.
Outline
- ViT Runtime & Efficiency Analyses
- EfficientViT
- Results
1. ViT Runtime & Efficiency Analyses
1.1. Runtime Analysis

- Memory access overhead is a critical factor affecting model speed.
- Red text denotes memory-bound operations, i.e., the time taken by the operation is mainly determined by memory accesses, while time spent in computation is much smaller.
Frequent reshaping, element-wise addition, and normalization are memory inefficient, requiring time-consuming access across different memory units.
This work is to save memory access cost by reducing memory-inefficient layers.
1.2. Memory Efficiency

- There are many small model variants for Swin and DeiT. The optimal allocation of MHSA and FFN layers is explored in small models with fast inference.
Subnetworks with 20%-40% MHSA layers tend to get better accuracy. Such ratios are much smaller than the typical ViTs that adopt 50% MHSA layers.
- Memory-bound operations is reduced to 44.26% of the total runtime in Swin-T-1.25× that has 20% MHSA layers.
Reducing MHSA layer utilization ratio appropriately can enhance memory efficiency while improving model performance.
1.3. Computation Efficiency
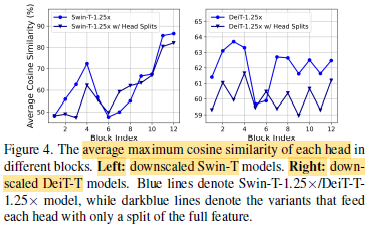
- Attention maps are computationally expensive.
- By using maximum cosine similarity of each head and the remaining heads within each block, it is found that there exists high similarities between attention heads.
Using different channel-wise splits of the feature in different heads, instead of using the same full feature for all heads as MHSA, could effectively mitigate attention computation redundancy, which is similar to the idea of group convolution in AlexNet and ResNeXt.
1.4. Parameter Efficiency

- Typical ViT uses an equivalent width for Q,K,V projections, increasing heads over stages, and setting the expansion ratio to 4 in FFN.
- Taylor structured pruning [53] is used to automatically find the important components in Swin-T and DeiT-T, and the underlying principles of parameter allocation is explored.
- The pruning method removes unimportant channels under a certain resource constraint and keeps the most critical ones to best preserve the accuracy. It uses the multiplication of gradient and weight as channel importance, which approximates the loss fluctuation when removing channels [38].
- The first two stages preserve more dimensions, while the last stage keeps much less;
- The Q, K and FFN dimensions are largely trimmed, whereas the dimension of V is almost preserved and diminishes only at the last few blocks.
2. EfficientViT

- Based on the above findings, EfficientViT is designed. It is composed of a memory-efficient sandwich layout, a cascaded group attention (CGA) module, and a parameter reallocation strategy.
2.1. Sandwich Layout
- Sandwich Layout employs less memory-bound self-attention layers and more memory-efficient FFN layers for channel communication.
Specifically, it applies a single self-attention layer ΦAi for spatial mixing, which is sandwiched between FFN layers ΦFi.

- where Xi is the full input feature for the i-th block.
The block transforms Xi into Xi+1 with N FFNs before and after the single self-attention layer.
- An extra token interaction layer is introduced before each FFN using a depthwise convolution (DWConv), which introduces inductive bias.
2.2. Cascaded Group Attention (CGA)
CGA feeds each head with different splits of the full features, thus explicitly decomposing the attention computation across heads. Formally, this attention can be formulated as:
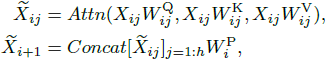
Additionally, the attention map of each head is calculated in a cascaded manner, which adds the output of each head to the subsequent head to refine the feature representations progressively:
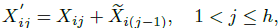
- Besides, another token interaction layer is applied after the Q projection, which enables the self-attention to jointly capture local and global relations and further enhances the feature representation.
Using different feature splits could improve the diversity of attention maps while cascading the attention heads allows for an increase of network depth.
2.3. Parameter Reallocation
- EfficientViT expands the channel width of critical modules while shrinking the unimportant ones.
- It sets small channel dimensions for Q and K projections in each head for all stages. For the V projection, it is allowed to have the same dimension as the input embedding.
- The expansion ratio in FFN is also reduced from 4 to 2 due to its parameter redundancy.
2.4. Model Variants & Others
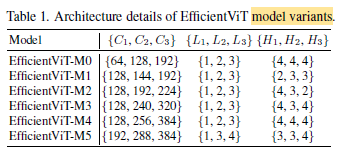
- Each stage stacks the proposed EfficientViT building blocks and the number of tokens is reduced by 4× at each subsampling layer.
- BN is used instead of LN. ReLU is used instead of GELU or HardSwish. And so on…
- Ci, Li, and Hi refer to the width, depth, and number of heads in the i-th stage. 6 variants are constructed as tabulated above.
3. Results
3.1. ImageNet-1K

The results show that, in most cases, EfficientViT achieves the best accuracy and speed trade-off across different evaluation settings.
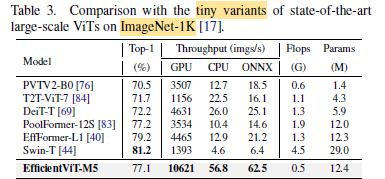
EfficientViT tiny variant has the highest throughput with acceptable accuracy performance.
3.2. Downstream Tasks
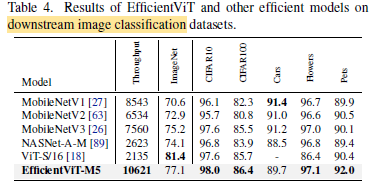
EfficientViT-M5 achieves comparable or slightly better accuracy across all datasets with much higher throughput. An exception lies in Cars, where the model is slightly inferior in accuracy.
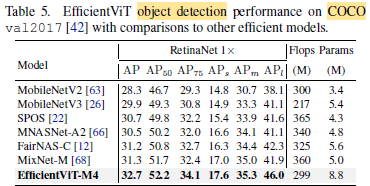
EfficientViT-M4 surpasses MobileNetV2 by 4.4% AP with comparable Flops.
- (For ablation studies, please read the paper directly if interested.)
