Brief Review — Nemotron-4 15B Technical Report
Nemotron-4 15B
4 min readJul 11, 2024
Nemotron-4 15B Technical Report
Nemotron-4 15B, by NVIDIA
2024 arXiv v2 (Sik-Ho Tsang @ Medium)Large Langauge Model (LLM)
2020 … 2023 [GPT-4] [LLaMA] [Koala] [BloombergGPT] [GLM-130B] [UL2] [PaLM 2] [Llama 2] [MultiMedQA, HealthSearchQA, Med-PaLM] [Med-PaLM 2] [Flan 2022, Flan-T5] [AlphaCode 2] [Mistral 7B]
==== My Other Paper Readings Are Also Over Here ====
- While Nemotron-4 340B has been published recently, in this paper Nemotron-4 15B is proposed, which is a 15-billion-parameter large multilingual language model trained on 8 trillion text tokens. (These 8T tokens are also used for pretraining Nemotron-4 340B.)
- Nemotron-4 15B demonstrates strong performance when assessed on English, multilingual, and coding tasks, outperforming all existing similarly-sized open models on 4 out of 7 downstream evaluation areas and achieves competitive performance to the leading open models in the remaining ones.
Outline
- Nemotron-4 15B
- Results
1. Nemotron-4 15B
1.1. Model Architecture

- Nemotron-4 uses a standard decoder-only Transformer architecture.
- Nemotron-4 has 3.2 billion embedding parameters and 12.5 billion non-embedding parameters.
- Nemotron-4 uses Rotary Position Embeddings (RoPE), SentencePiece tokenizer, squared ReLU activations in the MLP layers, no bias terms, Dropout rate of zero, and untied input-output embeddings.
- Grouped-Query Attention (GQA) is used for faster inference and lower memory footprint.

- Nemotron-4 was trained using 384 DGX H100 nodes; each node contains 8 H100 80GB SXM5 GPUs based on the NVIDIA Hopper architecture. Each H100 GPU has a peak throughput of 989 teraFLOP/s.
1.2. Pretraining Data
- Nemotron-4 15B is trained on a pre-training dataset consisting of 8 trillion tokens. At a high-level, the data blend is split into three different types of data: English natural language data (70%), multilingual natural language data (15%), and source-code data (15%).
- The final vocabulary size is 256,000 tokens.

- The English corpus consists of curated documents from a variety of sources and domains including web documents, news articles, scientific papers, books, etc.
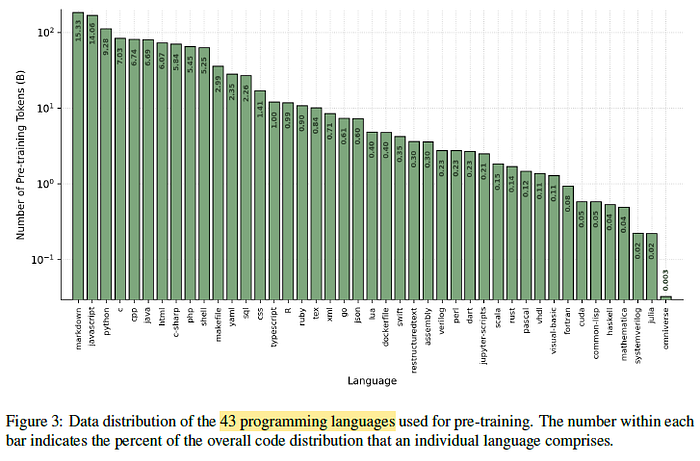
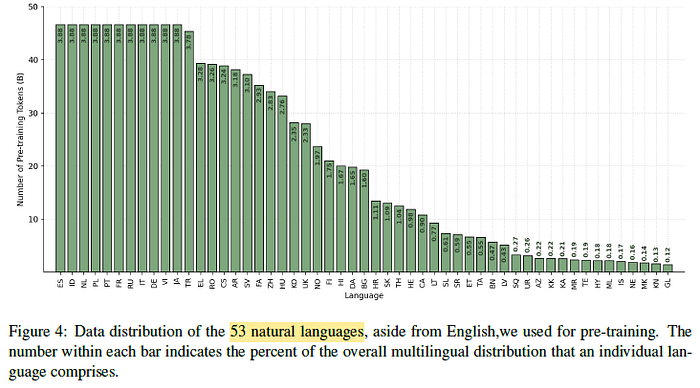
- The code and multilingual data consists of a diverse set of natural and programming languages.
- The appropriately sampling tokens from these languages is key to strong accuracies in these domains.
1.3. Continued Training
- Similar to recent work, Gemini, switching the data distribution and learning rate decay schedule at the end of model training greatly improves model quality.
2. Results

As demonstrated in Figure 1, Nemotron-4 15B exhibits high downstream accuracies across a wide range of English, code, and multilingual evaluation areas.
- In comparison to leading similarly-sized, open models, Nemotron-4 15B is significantly better than LLaMA-2 34B, which has over twice the number of parameters, and is better than Mistral 7B on all English evaluation areas.
- Additionally, Nemotron-4 15B achieves competitive accuracies to QWEN 14B and Gemma 7B.
- In a comparison across a wide range of programming languages, Nemotron-4 15B achieves better average accuracy, and in particular on low-resource programming languages, than Starcoder, a code-specific model, and Mistral 7B.
- As Nemotron-4 15B was trained on significant amount of multilingual data, it is currently the state-of-the-art general purpose model in its size class on all multilingual benchmarks. Nemotron-4 is better than PaLM 62B-Cont, and also outperforms multilingual-specific models such as XGLM and mGPT.
