Review — UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
UniLMv2, Jointly Train Autoencoding (AE), and Partially Autoregressive (PAR) Objectives

UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training,
UNILMv2, by Harbin Institute of Technology, and Microsoft Research,
2020 ICML, Over 200 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, LM, BERT
- A unified language model is pretrained for both autoencoding and partially autoregressive language modeling tasks using a novel training procedure, referred to as a pseudo-masked language model (PMLM).
- Conventional masks learn inter-relations between corrupted tokens and context via autoencoding, and pseudo masks to learn intra-relations between masked spans via partially autoregressive modeling.
Outline
- Unified Language Model Pre-Training v2 (UniLMv2)
- UniLMv2 Illustrative Example
- Results
1. Unified Language Model Pre-Training v2 (UniLMv2)


1.1. Autoencoding Modeling
- This is the same as in the BERT one.
- Given original input x=x1, …, x|x| and the positions of masks M={m1, …, m|M|}, the probability of masked tokens is computed by the product of probabilities below, where \ is the set minus to exclude the masked tokens.
- The autoencoding pre-training loss is defined as:

1.2. Partially Autoregressive Modeling

- In each factorization step, the model can predict one or multiple tokens.
- Let M=<M1, …, M|M|> denote factorization order, where Mi={mi1, …, mi|Mi|} is the set of mask positions in the i-th factorization step.
- If all factorization steps only contain one masked token (i.e., |Mi| = 1), the modeling becomes autoregressive.
In UniLMv2, the factorization step can be a span, which makes the LM partially autoregressive.
- The probability of masked tokens is decomposed as:

- The partially autoregressive pre-training loss is defined as:
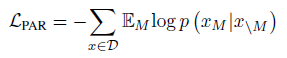
- where EM is the expectation over the factorization distribution.
- During pre-training, UniLMv2 randomly samples one factorization order M for each input text.
- As described in the above Algorithm, UniLMv2 randomly samples 15% of the original tokens as masked tokens. Among them, 40% of the time a n-gram block (n=6) is masked, and 60% of the time a token is masked.
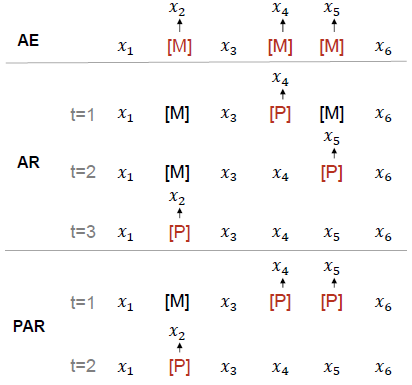
- The above figure shows the differences of AE, AR and proposed PAR.
- Both the special tokens [M] and [P] emit predicted tokens. The training objective is to maximize the likelihood of correct tokens, which considers two types of LMs:

- A model with the same model size as BERTBASE, i.e. a 12-layer Transformer with 12 attention heads, for ease of comparison.
- Relative position bias, as in Shaw NAACL’18, is added to attention scores.
- 160GB text corpora is used from English Wikipedia1, BookCorpus, OpenWebText2, CC-News, and Stories. Wordpiece tokenization is used. The vocabulary size was 30,522.
- The batch size was set to 7680. Pre-training procedure for 0.5 million steps is used, which took about 20 days using 64 Nvidia V100–32GB GPU cards.
2. UniLMv2 Illustrative Example

Vanilla MLMs allow all tokens to attend to each other, while PMLM controls accessible context for each token according to the factorization order.
- As shown above, the example’s factorization order is 4, 5 → 2.
- When we compute p(x4, x5|x\{2,4,5}), only x1, x3, x6 and the pseudo masks of x4, x5 are conditioned on. The original tokens of x4, x5 are masked to avoid information leakage, while their pseudo tokens [P] are used as placeholders for MLM predictions.
- In the second step, the tokens x1, x3, x4, x5, x6 and the pseudo mask of x2 are conditioned on to compute p(x2|x\{2}). Unlike in the first step, the original tokens of x4, x5 are used for the prediction.
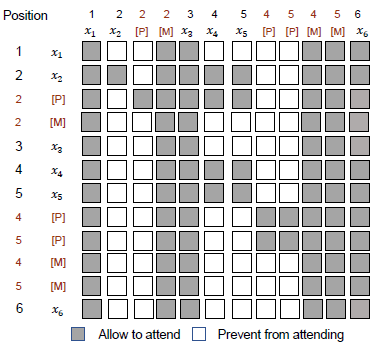
- The above figure shows the selfattention mask matrix used for the example. Both conventional masks [M] and given context (x1, x3, x6) can be attended by all the tokens.
3. Results
3.1. SQuaD & GLUE

Left: UniLMv2BASE achieves better performance than the other models on both SQuAD datasets.
Right: UniLMv2BASE outperforms both BERTBASE and XLNetBASE across 8 tasks. Comparing to state-of-the-art pre-trained RoBERTaBASE, UniLMv2BASE obtains the best performance on 6 out of 8 tasks, e.g., 88.4 vs 87.6 (RoBERTaBASE) in terms of MNLI accuracy, indicating the effectiveness of the UniLMv2BASE.
3.2. Abstractive Summarization
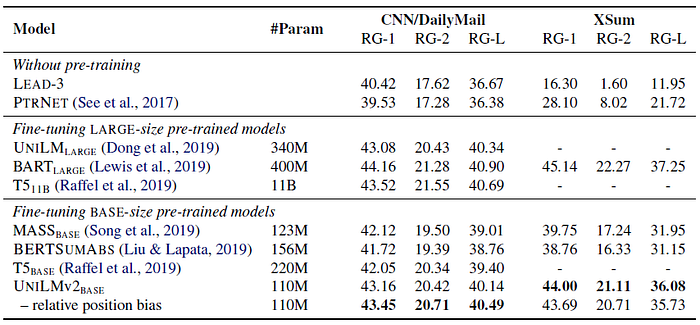
Although UniLMv2BASE has the smallest model size, it outperforms the other BASE-size pre-trained models on both datasets.
3.3. Question Generation
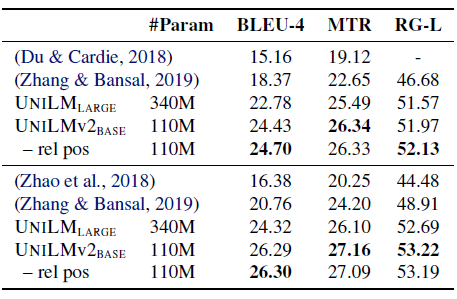
UniLMv2BASE achieves better evaluation metrics compared with UniLMLARGE and several baselines. It is worth noting that UniLMv2BASE consists of three times fewer parameters than UniLMLARGE.
3.4. Ablation Study

By removing one of the components (-), the results indicate that blockwise masking and factorization are important for LM pre-training.
Among the five objectives, AE+PAR performs the best with the help of PMLM, which shows that autoencoding and partially autoregressive modelings are complementary for pre-training.
Reference
[2020 ICML] [UniLMv2]
UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
2.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA] [Megatron-LM] [SpanBERT] [UniLMv2] 2021 [Performer] [gMLP]
