Review — Focal Transformer: Focal Self-attention for Local-Global Interactions in Vision Transformers
Surrounding Tokens, Fine Grained Attention; Tokens Far Away, Coarse Granularity

Focal Self-attention for Local-Global Interactions in Vision Transformers
Focal Transformer, by Microsoft Research at Redmond, and Microsoft Cloud + AI, 2021 NeurIPS, Over 100 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Transformer, Vision Transformer (ViT)
- A new mechanism, focal self-attention, is proposed to incorporate both fine-grained local and coarse-grained global interactions.
- Each token attends its closest surrounding tokens at fine granularity and the tokens far away at coarse granularity, and thus can capture both short- and long-range visual dependencies efficiently and effectively.
- With focal self-attention, a new variant of Vision Transformer models, called Focal Transformer, is formed.
Outline
- Focal Transformer Overall Architecture
- Focal Self Attention
- Experimental Results
- Ablation Studies
1. Focal Transformer Overall Architecture

- To accommodate the high-resolution vision tasks, the proposed model architecture shares a similar multi-scale design.
- An image I with the size of H×W×3 is first partitioned into patches of size 4×4, resulting in H/4×W/4 visual tokens with dimension 4×4×3.
- Then, a patch embedding layer is used, which consists of a convolutional layer with filter size and stride both equal to 4, to project these patches into hidden features with dimension d.
- Given this spatial feature map, it is then passed to four stages of focal Transformer blocks. At each stage i ∈ {1, 2, 3, 4}, the focal Transformer block consists of Ni focal Transformer layers. After each stage, another patch embedding layer is used to reduce the spatial size of feature map by factor 2, while the feature dimension is increased by 2.
- For image classification tasks, the average of the output from last stage is taken and sent to a classification layer.
- For object detection, the feature maps from last 3 or all 4 stages are fed to the detector head, depending on the particular detection method that is using.
- The model capacity can be customized by varying the input feature dimension d and the number of focal Transformer layers at each stage {N1, N2, N3, N4}.
If standard self-attention is used, it can capture both short- and long-range interactions at fine-grain, but it suffers from high computational cost, as well as an explosion of time and memory cost, especially the feature map is large.
- Thus, Focal Self Attention is proposed.
2. Focal Self Attention
2.1. Benefits of Focal Self Attention

- Focal self-attention helps to make Transformer layers scalable to high-resolution inputs.
- As shown above, for a query position, when gradually coarser-grain is used for its far surroundings, focal self-attention can have significantly larger receptive fields at the cost of attending the same number of visual tokens than the baseline.
- The proposed focal mechanism enables long-range self-attention with much less time and memory cost, because it attends a much smaller number of surrounding (summarized) tokens.
2.2. Window-Wise Focal Self Attention
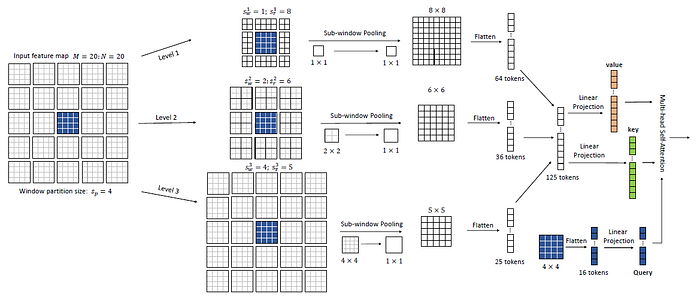
2.2.1. Illustrative Example
- Each of the finest square cell represents a visual token either from the original feature map or the squeezed ones.
- Suppose we have an input feature map of size 20×20. It is first partitioned it into 5×5 windows of size 4×4.
- Take the 4×4 blue window in the middle as the query, its surroundings tokens are extracted at multiple granularity levels as its keys and values.
- For the first level, the 8×8 tokens are extracted which are closest to the blue window at the finest grain.
- Then at the second level, the attention region is expanded and the surrounding 2×2 sub-windows are pooled, which results in 6×6 pooled tokens.
- At the third level, even larger region covering the whole feature map is attended and 4×4 sub-windows are pooled.
- Finally, these three levels of tokens are concatenated to compute the keys and values for the 4×4=16 tokens (queries) in the blue window:
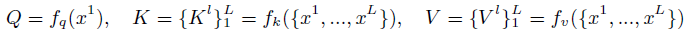
2.2.2. Model Variants
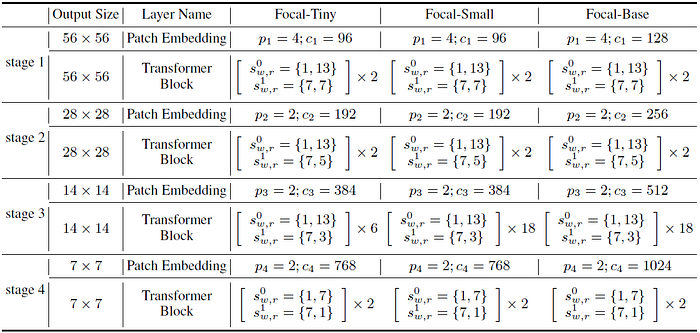
- Three terms are defined to generate different model variants:
- Focal levels L: The number of granularity levels to extract the tokens for focal self-attention. In the first figure, there are 3 focal levels.
- Focal window size slw: The size of sub-window on which the summarized tokens are obtained at level l ∈ {1, …, L}, which are 1, 2 and 4 for the three levels in the first figure.
- Focal region size slr: The number of sub-windows horizontally and vertically in attended regions at level l. They are 3, 4 and 4 from level 1 to 3 in the first figure.
- Similar design as in Swin Transformer is used to define the Tiny, Small and Base models, with the use of different L, slw and slr.
3. Experimental Results
3.1. ImageNet-1K

Focal Transformers consistently outperforms other methods with similar model size (#Params.) and computational complexity (GFLOPs).
- Specifically, Focal-Tiny improves over the Transformer baseline DeiT-Small/16 by 2.0%.
- Focal-Tiny improves over Swin-Tiny by 1.0 point (81.2% → 82.2%).
- When the window size is increased from 7 to 14 to match the settings in ViL-Small, the performance can be further improved to 82.5%.
- Notably, Focal-Small with 51.1M parameters can reach 83.5% which is better than all counterpart small and base models using much less parameters.
- When further increasing the model size, Focal-Base model achieves 83.8%, surpassing all other models using comparable parameters and FLOPs.
3.2. Object Detection and Instance Segmentation
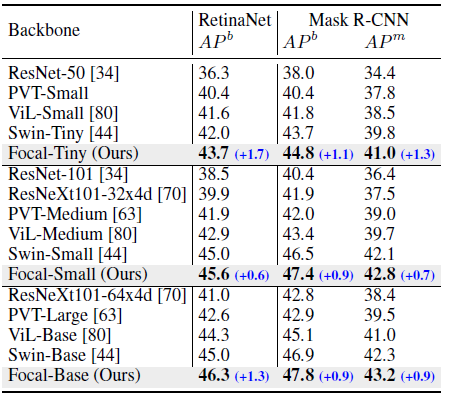
- RetinaNet and Mask R-CNN are used as object detector.
- Focal Transformers outperform the CNN-based models consistently with the gap of 4.8–7.1 points.
- Focal Transformers brings 0.7–1.7 points of mAP against the current best approach Swin Transformer.
Focal Transformers can simultaneously enable short-range fine-grain and long-range coarse-grain interactions for each visual token, and thus capture richer visual contexts at each layer for better dense predictions.
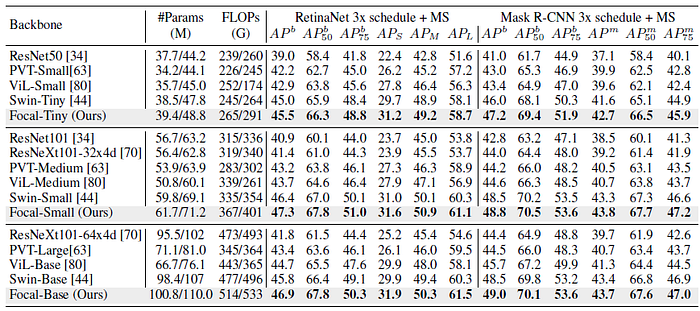
For 3× schedule, Focal Transformers can still achieve 0.3–1.1 gain over the best Swin Transformer models at comparable settings.
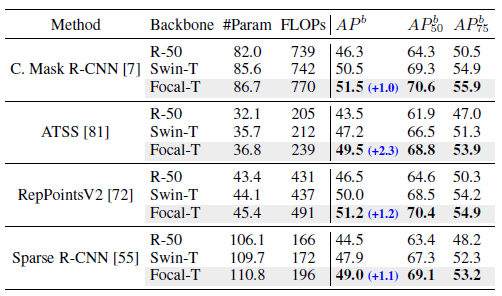
- Other detection methods are also tried using 3× schedule.
Focal-Tiny exceeds Swin-Tiny by 1.0–2.3 points on all methods.
3.3. Semantic Segmentation

The proposed tiny, small and base models consistently outperform Swin Transformers with similar size on single-scale and multi-scale mIoUs.
- Focal-Large has more than 1 point mIoU improvement, which presents a new SoTA for semantic segmentation on ADE20K, verifying that the effectiveness of the proposed focal self-attention mechanism in capturing long-range dependencies required by dense visual prediction tasks.
3.4. SOTA Comparison
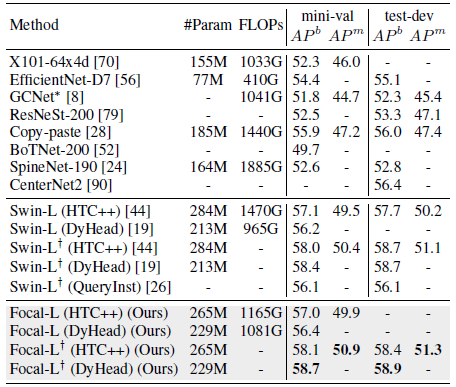
Focal Large model is built by increasing the hidden dimension in Focal-Base from 128 to 196.
- To get the best performance, the common practice is to pretrain on ImageNet-22K and then transfer the model to downstream tasks. However, due to the limited resources, the proposed model is partially initialized with the pretrained Swin Transformer checkpoint. Then, the model is fine-tuned on ImageNet-1K to learn the focal-specific parameters. The resulting model is used as the backbone and further fine-tuned on object detection and semantic segmentation tasks.
Focal-Large model with multi-scale test achieve 58.1 box mAP and 50.9 mask mAP on mini-val set, which are better than the reported numbers for Swin-Large.
When evaluating the proposed model on the test-dev set, it achieves 58.4 box mAP and 51.3 mask mAP, which is slightly better than Swin Transformer.
- More recently, DyHead [19] achieves new SoTA on COCO, when combined with Swin-Large. The Swin-Large model is replaced with our Focal-Large model, and the same 2× training schedule is used.
Focal-Large clearly bring substantial improvements over both metrics, reaching new SoTA on both metrics.
4. Ablation Studies
4.1. Effect of Varying Window Size

The default size 7 is changed to 14 and consistent improvements are observed for both methods.
4.2. The Necessity of Window Shift
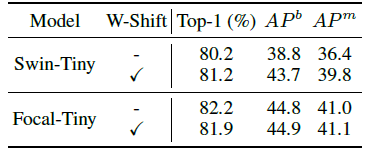
- In Swin Transformer, there is window shift. Swin Transformer shows a severe degradation after removing the window shift.
However, Focal Transformer is even hurt on classification task. These results indicate that the window shift is not a necessary ingredient in the proposed model.
4.3. Contributions of Short- and Long-Range Interaction
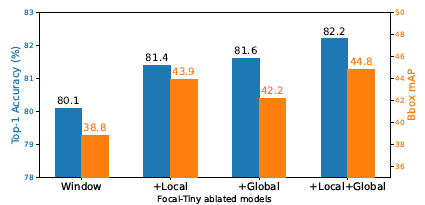
- The effect of short-range fine-grain and long-range coarse-grain interactions are factorized in Focal Transformers for ablation study.
- a) Focal-Tiny-Window merely performing attention inside each window; b) Focal-Tiny-Local attending the additional fine-grain surrounding tokens and c) Focal-Tiny-Global attending the extra coarse-grain squeezed tokens.
- Focal-Tiny-Window suffers from significant drop.
After enabling either the local fine-grain or global coarse-grain interactions (middle two columns), significant jumps are observed.
Combining them obtains even larger jumps.
- Adding long-range tokens can bring more relative improvement for image classification than object detection and vice versa for local tokens. It is suspected that dense predictions like object detection more rely on fine-grained local context while image classification favors more the global information.
4.4. Model Capacity Against Model Depth
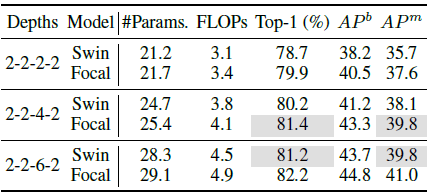
First, it is found that the proposed model outperforms Swin model consistently with the same depth.
More importantly, using two less layers, the proposed model achieves comparable performance to Swin Transformer.
- Particularly, Focal-Tiny with 4 layers achieves 81.4 on image classification which is even better than original Swin-Tiny model with 6 layers (highlighted in gray cells).
Reference
[2021 NeurIPS] [Focal Transformer]
Focal Self-attention for Local-Global Interactions in Vision Transformers
Image Classification
1989 … 2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1] [CvT] [HaloNet] [TNT] [CoAtNet] [Focal Transformer]
