Brief Review — GLM-130B: An Open Bilingual Pre-trained Model
GLM-130B, Supports Both Chinese & English, Outperforms GPT-3, OPT, BLOOM, PaLM

GLM-130B: An Open Bilingual Pre-trained Model,
GLM-130B, by Tsinghua University, and Zhipu.AI,
2023 ICLR (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] [OPT] [Switch Transformers] [LaMDA] [LoRA] [Galactica] 2023 [GPT-4] [LLaMA] [LIMA] [Koala] [BloomBergGPT]
==== My Other Paper Readings Are Also Over Here ====
- GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters is proposed, with design choices, training strategies used for both efficiency and stability.
- ChatGLM is developed based on GLM-130B: https://chatglm.cn/
Outline
- GLM-130
- Results
1. GLM-130
1.1. Model
- GLM is used as Backbone, which is a transformer-based language model that leverages autoregressive blank infilling as its training objective.
- In brief, for a text sequence, there is random spanned token masked, also random single tokens masked. The model is asked to recover them autoregressively. The corresponding objective function is:

- (Please feel free to read GLM for more details.)

- Post-LN initialized with the newly-proposed DeepNorm, as in DeepNet, is used for training stability.
- Rotary Positional Encoding (RoPE) is used for positonal embedding.
- To improve FFNs in Transformer, GLU with the GeLU is used.
1.2. Corpus
- The pre-training data includes 1.2T Pile (Gao et al., 2020) English corpus, 1.0T Chinese Wudao-Corpora (Yuan et al., 2021), and 250G Chinese corpora.
- Multi-Task Instruction Pre-Training (MIP, 5% tokens) is used.
1.3. Platform
- GLM-130B is trained on a cluster of 96 DGX-A100 GPU (840G) servers with a 60-day access. The data parallelism and tensor model parallelism are used.
- FP16 for forwards and backwards and FP32 for optimizer states and master weights, to reduce the GPU memory usage and improve training efficiency.

- There is spike in pretraining loss, which can cause training failure. The gradient shrink on the embedding layer can help overcome loss spikes:

1.4. Inference
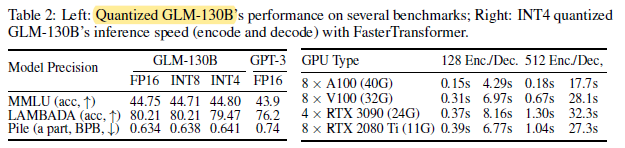
- FasterTransformer is leveraged to implement GLM-130B in C++.
- INT4 quantization of model weights (i.e., mostly linear layers) are used while keeping the FP16 precision for activations.
- This can help saving half of the required GPU memory to 70GB, thus allowing GLM-130B inference on 4× RTX 3090 Ti (24G) or 8× RTX 2080 Ti (11G), with nearly no performance degradation.
2. Results

For zero-shot performance, GLM-130B is better than GPT-3 175B (+5.0%), OPT-175B (+6.5%), and BLOOM-176B (+13.0%) on LAMBADA, and achieves 3× better performance than GPT-3 on Big-bench-lite.
For the 5-shot MMLU (Hendrycks et al., 2021) tasks, it is better than GPT-3 175B (+0.9%) and BLOOM-176B (+12.7%).
As a bilingual LLM also in Chinese, it offers significantly better results than ERNIE TITAN 3.0 260B — the largest Chinese LLM — on 7 zero-shot CLUE datasets (+24.26%) and 5 zero-shot FewCLUE ones (+12.75%).
Importantly, as summarized in Figure 1(b), GLM-130B as an open model is associated with significantly less bias and generation toxicity than its 100B-scale counterparts.
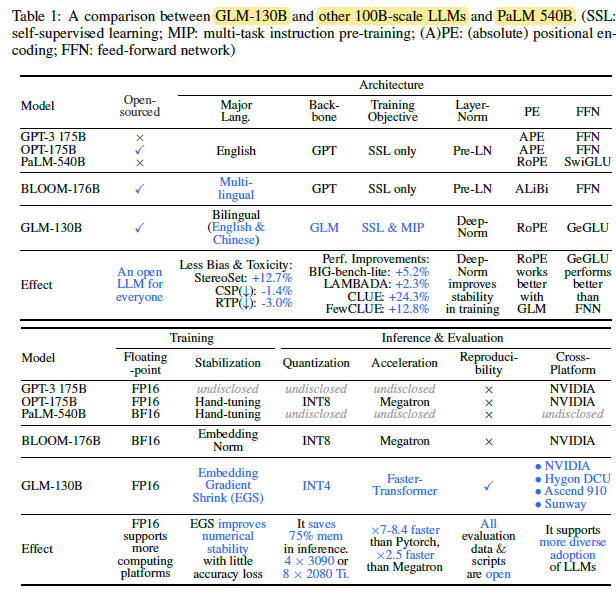
GLM-130B to exhibit performance that surpasses the level of GPT-3 on a wide range of benchmarks (in total 112 tasks) and also outperforms PaLM 540B in many cases, while outperformance over GPT-3 has not been observed in OPT-175B and BLOOM-176B.
- (Please feel free to read the paper directly for more details.)
