Review — MViT: Multiscale Vision Transformers
MViT/MViTv1, Proposed Pooling Attention, Reduce Dimensions

Multiscale Vision Transformers,
MViT/MViTv1, by Facebook AI Research (FAIR), UC Berkeley,
2021 ICCV, Over 300 Citations (Sik-Ho Tsang @ Medium)
Video Classification, Action Recognition, Image Classification, Vision Transformer, ViT, Swin Transformer
- Multiscale Vision Transformer (MViT) is proposed for video classification, which creates a multiscale pyramid of features.
- Early layers operate at high spatial resolution to model simple low-level visual information, and deeper layers operate at spatially coarse resolution, but to model complex, high-dimensional features, as below.
- When number of input frames is reduced to 1, it can be used for image classification as well.
Outline
- Multi Head Pooling Attention (MHPA)
- Multiscale Vision Transformer (MViT)
- Video Classification Results
- Image Classification Results
1. Multi Head Pooling Attention (MHPA)

- MHPA pools the sequence of latent tensors to reduce the sequence length (resolution) of the attended input.
- Following ViT, MHPA projects the input X into intermediate query tensor ^Q, key tensor ^K and value tensor ^V:

- Then, ^Q, ^K, ^V are pooled with the pooling operator P(;) which is the cornerstone of the MHPA:

- Attention is now computed on these shortened vectors:

In summary, pooling attention is computed as:

- Similar to ViT, the below is the Transformer block with MHA then MLP, with the use of Layer Norm and skip connection:


By the pooling attention, early layers operate at high spatial resolution to model simple low-level visual information, and deeper layers operate at spatially coarse resolution, but to model complex, high-dimensional features, as below.
- (There are other implementation details, please feel free to read the paper.)
2. Multiscale Vision Transformer (MViT)

- A scale stage is defined as a set of N Transformer blocks that operate on the same scale.
- ViT (Left): always uses the same scale at scale2.
- MViT (Right): There are multiple scale stages, to downsize the tensors for attention, which makes it more memory and compututionally efficient.
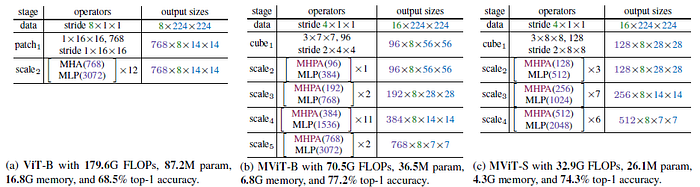
As shown above, MViT-B and MViT-S are more efficient than ViT-B.
3. Video Classification Results
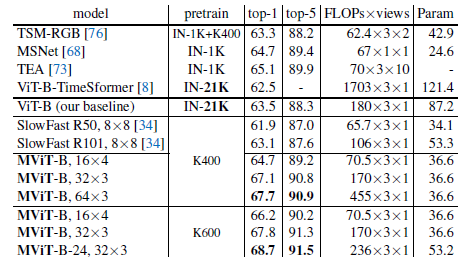
3.1. Kinetics-400


- T×τ: A T×τ clip from the full-length video which contains T frames with a temporal stride of τ.
For small model, MViT-S produces 76.0% while being relatively lightweight with 26.1M param and 32.9×5=164.5G FLOPs, outperforming ViT-B by +7.5% at 5.5× less compute in identical train/val setting.
For base model, MViT-B provides 78.4%, a +9.9% accuracy boost over ViT-B under identical settings, while having 2.6×/2.4× fewer FLOPs/parameters.
3.2. Kinetics-600
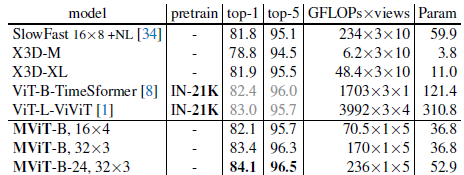
MViT achieves state-of-the-art of 83.4% with 5-clip center crop testing while having 56.0× fewer FLOPs and 8.4× fewer parameters than ViT-L-ViViT.
3.3. Something-Something-v2 (SSv2)
MViT-B with 16 frames has 64.7% top-1 accuracy, which is better than the SlowFast R101. WIth more input frames or/and deeper, it is even better.
3.4. Charades

With similar FLOPs and parameters, MViT-B 16×4 achieves better results (+2.0 mAP) than SlowFast R50.
3.5. AVA v2.2
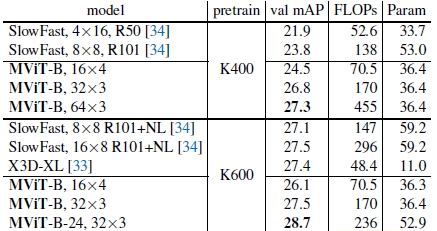
MViT-B can be competitive to SlowFast and X3D using the same pre-training and testing strategy.
- (There are other ablation experiments, please feel free to read the paper.)
4. Image Classification Results

- With single frame as input, it becomes an image classification model.
Compared to the best model of concurrent Swin Transformer (which was designed for image recognition), MViT has +0.6% better accuracy at 1.4× less computation.
In this paper, MViT/MViTv1 primarily works on video classification and extends to image classification. Later on, MViTv2 is proposed in 2022 CVPR. MViTv2 rather works on image classification and extends to object detection and video classification tasks.
Reference
[2021 ICCV] [MViT / MViTv1]
Multiscale Vision Transformers
[GitHub] [PySlowFast]
https://github.com/facebookresearch/SlowFast
1.1. Image Classification
1989 … 2021 [MViT / MViTv1] … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer] [Sparse MLP]
1.11. Video Classification / Action Recognition
2014 … 2019 [VideoBERT] [Moments in Time] 2021 [MViT]
