Review — Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
PVT: Pyramid Vision Transformer, Progressive Shrinking Pyramid

Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
PVT, PVTv1, by Nanjing University, The University of Hong Kong, Nanjing University of Science and Technology, IIAI, SenseTime Research
2021 ICCV, Over 400 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Object Detection, Semantic Segmentation, Instance Segmentation, Transformer, ViT
- Pyramid Vision Transformer (PVT), achieves high output resolution, which overcomes the difficulties of porting Transformer, e.g. ViT in (b), to various dense prediction tasks in (c).
- A progressive shrinking pyramid is proposed to reduce the computations, inherits the advantages of both CNN and Transformer, which could serve as an alternative and useful backbone for pixel-level predictions.
Outline
- Pyramid Vision Transformer (PVT)
- Discussions about ViT and PVT
- Experimental Results
1. Pyramid Vision Transformer (PVT)

1.1. Overall Architecture
- The entire model is divided into four stages, each of which is comprised of a patch embedding layer and a Li-layer Transformer encoder. Following a pyramid structure, the output resolution of the four stages progressively shrinks from high (4-stride) to low (32-stride).
- In the first stage, given an input image of size H×W×3, it is first divided into HW/4² patches, each of size 4×4×3.
- Then, the flattened patches are fed to a linear projection and embedded patches of size HW/4² ×C1 are obtained.
- After that, the embedded patches along with a position embedding are passed through a Transformer encoder with L1 layers, and the output is reshaped to a feature map F1 of size H/4×W/4 ×C1.
1.2. Feature Pyramid for Transformer
- In the same way, using the feature map from the previous stage as input, the following feature maps are obtained: F2, F3, and F4, whose strides are 8, 16, and 32 pixels with respect to the input image.
Thus, PVT uses a progressive shrinking strategy to control the scale of feature maps by patch embedding layers. The feature pyramid {F1, F2, F3, F4} are obtained.
1.3. Transformer Encoder
- Since PVT needs to process high-resolution (e.g., 4-stride) feature maps, a spatial-reduction attention (SRA) layer is proposed to replace the traditional multi-head attention (MHA) layer in the encoder.
- Similar to MHA, the proposed SRA receives a query Q, a key K, and a value V as input, and outputs a refined feature.
- The difference is that the proposed SRA reduces the spatial scale of K and V before the attention operation, which largely reduces the computational/memory overhead.


- where SR is the operation for reducing the spatial dimension of the input sequence (i.e., K or V), which is written as:
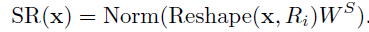
- With Ws is the linear projection that reduces the dimension of the input sequence to Ci, and Reshape(x, Ri) is an operation of reshaping the input sequence x to a sequence of size:
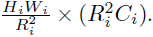
- And the attention operation Attention(·) is calculated as in the original Transformer:
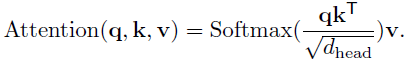
The computational/memory costs of attention operation are R²i times lower than those of MHA, so the proposed SRA can handle larger input feature maps/sequences with limited resources.
1.4. PVT Variants
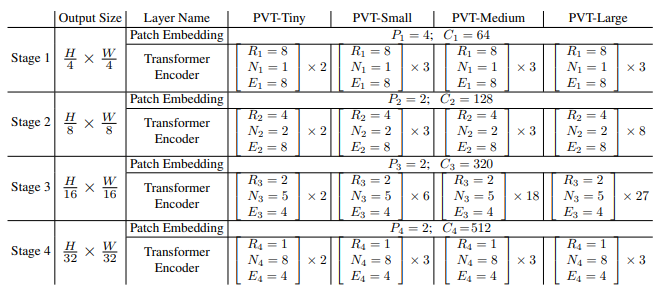
- PVT-Tiny, PVT-Small, PVT-Medium, PVT-Large are designed as above.
2. Discussions about ViT and PVT
2.1. ViT Limitation
- Due to the limited resource, the input of ViT is coarse-grained (e.g., the patch size is 16 or 32 pixels), and thus its output resolution is relatively low (e.g., 16-stride or 32-stride). As a result, it is difficult to directly apply ViT to dense prediction tasks that require high-resolution or multi-scale feature maps.
2.2. PVT advantages over ViT:
- more flexible — can generate feature maps of different scales/channels in different stages;
- more versatile — can be easily plugged and played in most downstream task models;
- more friendly to computation/memory — can handle higher resolution feature maps or longer sequences.
3. Experimental Results
3.1. Image Classification on ImageNet

The proposed PVT models are superior to conventional CNN backbones under similar parameter numbers and computational budgets.
- For example, when the GFLOPs are roughly similar, the top-1 error of PVT-Small reaches 20.2, which is 1.3 points higher than that of ResNet50 (20.2 vs. 21.5).
- PVT models also achieves performances comparable to the recently proposed Transformer-based models, such as ViT and DeiT (PVT-Large: 18.3 vs. ViT(DeiT)-Base/16: 18.3).
Though little improvements are brought to image classification for Transformer series, ViT and DeiT have limitations as they are specifically designed for classification tasks, and thus are not suitable for dense prediction tasks.
3.2. Object Detection and Instance Segmentation on COCO
- PVT backbones are placed on top of two standard detectors, namely RetinaNet and Mask R-CNN.
3.2.1. PVT on RetinaNet
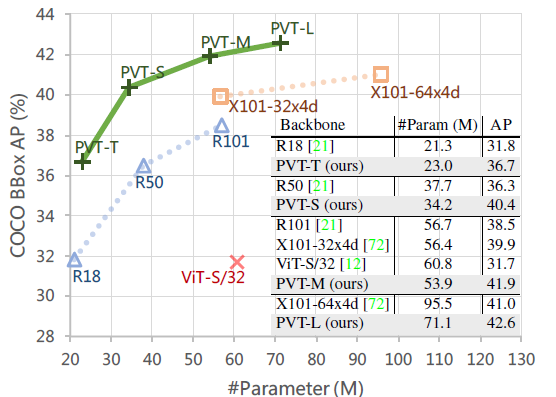
In terms of AP-Parameter tradeoff, PVT variants significantly outperform their corresponding counterparts such as ResNets (R), ResNeXts (X), and ViT.

PVT-based models significantly surpasses their counterparts. For example, with the 1× training schedule, the AP of PVT-Tiny is 4.9 points better than that of ResNet18 (36.7 vs. 31.8).
- Moreover, with the 3× training schedule and multi-scale training, PVT-Large archive the best AP of 43.4, surpassing ResNeXt101–64×4d (43.4 vs. 41.8), while parameter number is 30% fewer.
3.2.2. PVT on Mask R-CNN
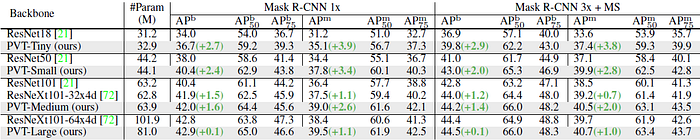
- With the 1× training schedule, PVT-Tiny achieves 35.1 mask AP (APm), which is 3.9 points better than ResNet18 (35.1 vs. 31.2) and even 0.7 points higher than ResNet50 (35.1 vs. 34.4).
The best APm obtained by PVT-Large is 40.7, which is 1.0 points higher than ResNeXt101–64x4d (40.7 vs. 39.7), with 20% fewer parameters.
3.3. Semantic Segmentation
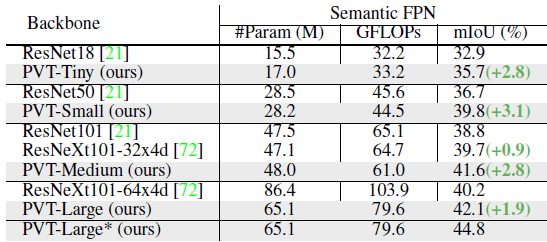
PVT-based models consistently outperforms the models based on ResNet or ResNeXt. For example, with almost the same number of parameters and GFLOPs, PVT-Tiny/Small/Medium are at least 2.8 points higher than ResNet-18/50/101.
- In addition, although the parameter number and GFLOPs of PVT-Large are 20% lower than those of ResNeXt101–64x4d, the mIoU is still 1.9 points higher (42.1 vs. 40.2).
With a longer training schedule and multi-scale testing, PVT-Large+Semantic FPN archives the best mIoU of 44.8, which is very close to the state-of-the-art performance of the ADE20K benchmark.
3.4. Pure Transformer Object Detection

- To reach the limit of no convolution, a pure Transformer pipeline is built for object detection by simply combining PVT with a Transformer-based detection head — DETR.
- PVT-based DETR achieves 34.7 AP on COCO val2017, outperforming the original ResNet50-based DETR by 2.4 points (34.7 vs. 32.3).
These results prove that a pure Transformer detector can also works well in the object detection task.
3.5. ViT vs PVT on Object Detection

- When using fine-grained image patches (e.g., 4×4 pixels per patch) as input like PVT, ViT will exhaust the GPU memory (32G).
- PVT avoids this problem through a progressive shrinking pyramid.
Specifically, PVT can process high-resolution feature maps in shallow stages and low-resolution feature maps in deep stages. Thus, it obtains a promising AP of 40.4 on COCO val2017, 8.7 points higher than ViT-Small/32 (40.4 vs. 31.7).
3.6. Computation Overhead
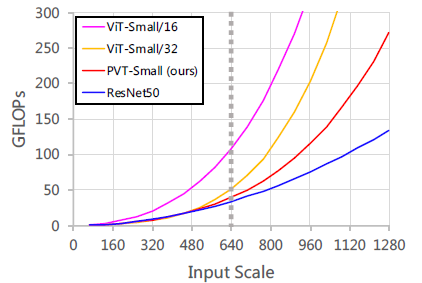
The growth rate of GFLOPs: ViT-Small/16 >ViT-Small/32 >PVT-Small >ResNet50.
3.7. Qualitative Results

Later, PVTv2 is proposed.
Reference
[2021 ICCV] [PVT, PVTv1]
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
Image Classification
1989 … 2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1]
Object Detection
2014 … 2021: [Scaled-YOLOv4] [PVT, PVTv1]
