Review — ResMLP: Feedforward Networks for Image Classification with Data-Efficient Training
No CNNs, No Transformers, Only MLPs
ResMLP: Feedforward Networks for Image Classification with Data-Efficient Training, ResMLP, by Facebook AI, Sorbonne University, Inria, and valeo.ai, 2021 arXiv v2, Over 30 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Machine Translation
- ResMLP is proposed where it is built entirely upon multi-layer perceptrons (MLP). It is a simple residual network that alternates:
- A linear layer in which image patches interact, independently and identically across channels, and
- A two-layer feed-forward network in which channels interact independently per patch.
Outline
- ResMLP Architecture
- Experimental Results
1. ResMLP Architecture

1.1. Advantages
- The ResMLP architecture is strongly inspired by the vision transformers (ViT), yet it is much simpler in several ways:
- The self-attention sublayer is replaced by a linear layer, resulting in an architecture with only linear layers and GELU non-linearity.
- The training of ResMLP is more stable than ViTs when using the same training scheme as in DeiT and CaiT, allowing to remove the need for batch-specific or cross-channel normalizations such as BatchNorm, GroupNorm or LayerNorm. It is speculated that this stability comes from replacing self-attention with linear layers.
- Finally, another advantage of using a linear layer is that by visualizing the interactions between patch embeddings, revealing filters that are similar to convolutions on the lower layers, and longer range in the last layers.
1.2. Overall
- ResMLP takes a grid of N×N nonoverlapping patches as input, where the patch size is typically equal to 16×16. The patches are then independently passed through a linear layer to form a set of N² d-dimensional embeddings.
- These N² embeddings are fed to a sequence of Residual Multi-Layer Perceptron layers to produce a set of N² d-dimensional output embeddings.
- These output embeddings are then averaged (“average-pooling”) as a d-dimension vector to represent the image, which is fed to a linear classifier to predict the label associated with the image.
- Training uses the cross-entropy loss.
1.3. The Residual Multi-Perceptron Layer
- Similar to Transformer, each sublayer is with a skip-connection.
- The absence of self-attention layers makes the training more stable, allowing us to replace the Layer Normalization by a simpler Affine transformation:

- where α and β are learnable weight vectors. This operation only rescales and shifts the input element-wise.
- First, as opposed to Layer Normalization, it has no cost at inference time, since it can absorbed in the adjacent linear layer.
- Second, as opposed to BatchNorm and Layer Normalization, the Aff operator does not depend on batch statistics.
- The closer operator to Aff is the LayerScale introduced by CaiT, with an additional bias term.
- For convenience, Aff(X) denotes the Affine operation applied independently to each column of the matrix X.
Aff operator is placed at the beginning (“pre-normalization”) and end (“post-normalization”) of each residual block.
- Multi-layer perceptron takes a set of N² d-dimensional input features stacked in a d N² matrix X, and outputs a set of N² d-dimension output features, stacked in a matrix Y with the following set of transformations:

- where A, B and C are the main learnable weight matrices of the layer.
1.4. Differences from ViT
- No self-attention blocks: Replaced by a linear layer with no non-linearity.
- No positional embedding: The linear layer implicitly encodes information about patch positions.
- No extra “class” token: Average pooling is simply used on the patch embeddings.
- No normalization based on batch statistics: Only learnable affine operator.
2. Experimental Results
2.1. ImageNet

- While the trade-off between accuracy, FLOPs, and throughput for ResMLP is not as good as convolutional networks or Transformers, their strong accuracy still suggests that the structural constraints imposed by the layer design do not have a drastic influence on performance.

- The accuracy obtained with ResMLP is lower than ViT. Nevertheless, the performance is surprisingly high for a pure MLP architecture and competitive with Convnet in k-NN evaluation.
- (Hope I can review DINO later in the future.)
2.2. Ablation Study
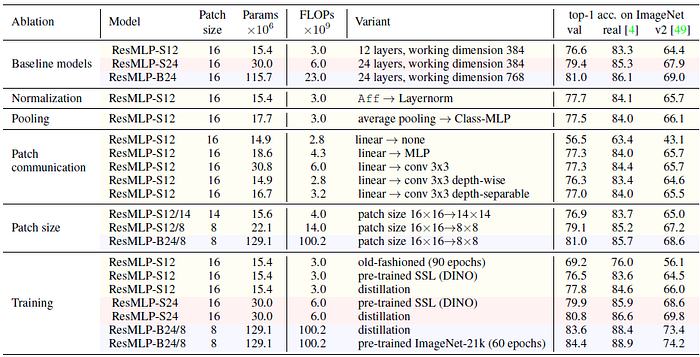
- ResMLP greatly benefits from distilling from a convnet. The DeiT training procedure improves the performance of ResMLP-S12 by 7.4%.
- Smaller patches benefit more to larger models, but only with an improved optimization scheme involving more regularization (distillation) or more data.
2.3. Transfer Learning
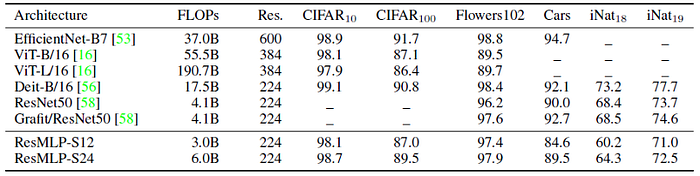
- ResMLP is competitive with the existing architectures.
2.4. Machine Translation

- ResMLP Models of dimension 512, with a hidden MLP size of 2,048, and with 6 or 12 layers.
- 6-layer model is more comparable to the base Transformer model and better than GNMT and ConvS2S in some cases.
Unfortunately, while the paper is very close to the acceptance threshold, it has been rejected in 2021 NeurIPS. (From OpenReview)
Reference
[2021 arXiv] [ResMLP]
ResMLP: Feedforward Networks for Image Classification with Data-Efficient Training
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL] [ciFAIR] [ResNeSt]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP]
Machine Translation
2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE] [GMNMT] 2019 [AdaNorm] 2021 [ResMLP]
