Review — SE-WRN: Squeeze-and-Excitation Wide Residual Networks in Image Classification
Squeeze-and-Excitation (SE) Attention Applied onto Wide Residual Networks (WRN)

Squeeze-and-Excitation Wide Residual Networks in Image Classification
SE-WRN, by Wuhan University of Technology, Hubei Province Key Laboratory of Transportation Internet of Things, and Wuhan University
2019 ICIP (Sik-Ho Tsang @ Medium)
Outline
- SE-WRN
- Experimental Results
1. SE-WRN

- Let B(M) denote residual block structure, where M is a list with the kernel sizes of the convolutional layers in a block.
- B(3,3) denotes a residual block with two 3×3 layers.
- WRN-n-k denotes a residual network that has a total number of convolutional layers n and a widening factor k (for example, network with 26 layers and k=10 times wider than origin would be denoted as WRN-26–10).

- rSE-ResNet-Block is used instead of the conventional SE-ResNet-Block in SENet.
- The global covariance pooling replaces the common first-order, max/average pooling after the last conv layer, producing a global, d(d + 1)/2 dimensional image representation by concatenation of the upper triangular part of one covariance matrix.
- A Dropout SE-block is used. The Dropout layer is added before the last FC layer in SE-block.
- Following [18], a 1×1 conv layer of 256 channels is added after the last conv layer when k>4, so that the dimension of features inputted to the global covariance pooling layer is fixed to 256, which will reduce the number of parameters.
2. Experimental Results

- The accuracy of the WRN-20–1 on CIFAR10 bellows 93%, which results with too little channel information.
As the channels are effectively utilized, the performance of the classification gradually increases.
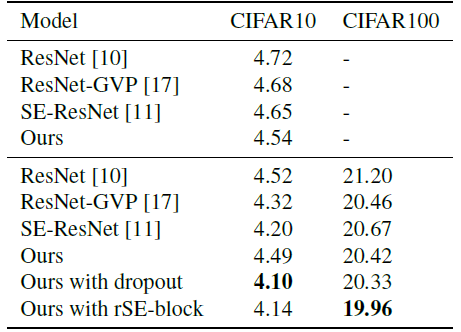
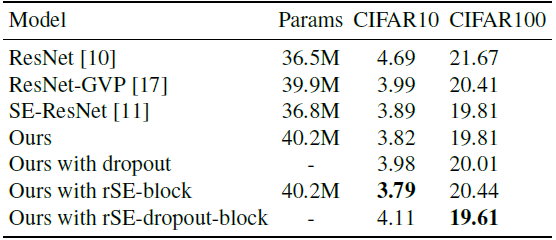
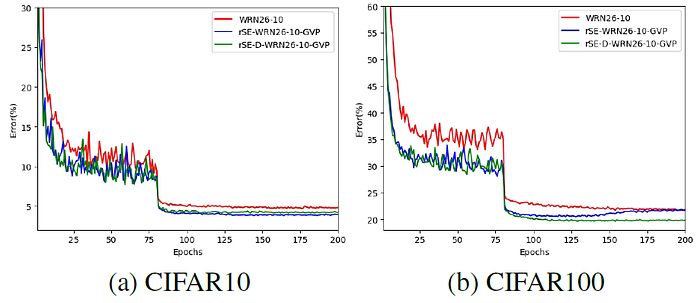
- WRN-26–10 is taken as the basic network.
- The proposed networks impose only a slight increase in model complexity and computational burden.
Reference
[2019 ICIP] [SE-WRN]
Squeeze-and-Excitation Wide Residual Networks in Image Classification
Image Classification
1989–2018 … 2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss] [AutoAugment, AA] [BagNet] [Stylized-ImageNet] [FixRes] [Ramachandran’s NeurIPS’19] [SE-WRN]
2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet]
2021: [Learned Resizer]
