Review — T-DMCA: Generating Wikipedia by Summarizing Long Sequences
T-DMCA, Reduce Memory of Transformer for Long Sequences
Generating Wikipedia by Summarizing Long Sequences,
(T-DMCA), by Google Brain.
- Generating English Wikipedia articles can be approached as a multi-document summarization of source documents.
- Extractive summarization is used to coarsely identify salient information and a neural abstractive model is used to generate the article.
- For the abstractive model, a decoder-only Transformer architecture is used that can scalably attend to very long sequences.
This is a paper in 2018 ICLR with over 400 citations. (Sik-Ho Tsang @ Medium)
Outline
- WikiSum Summarization Datasets
- Abstractive Model Using Transformer Decoder with Memory-Compressed Attention (T-DMCA)
- Experimental Results
1. WikiSum Summarization Datasets

- The input and output text are generally much larger, with significant variance depending on the article in the multi-document regime with Wikipedia.
- ROUGE is an automatic metric often used in summarization.
- The ROUGE-1 recall scores of the output given the input, which is the proportion of unigrams/words in the output co-occurring in the input. A higher score corresponds to a dataset more amenable to extractive summarization.
- In particular, if the output is completely embedded somewhere in the input (e.g. a wiki-clone), the score would be 100. Given a score of only 59.2 compared to 76.1 and 78.7 for other summarization datasets shows that WikiSum is the least amenable to purely extractive methods.

- The proposed WikiSum dataset also includes:
- Cited sources: A Wikipedia article that conforms to the style guidelines should be well supported by citations.
- Web Search results: To expand the collection of reference documents, the search results from the Google search engine are also crawled.
- The articles are roughly divided into 80/10/10 for train/development/ test subsets, resulting in 1865750, 233252, and 232998 examples respectively.
1.2. Extractive stage & Abstractive Stage
- It is infeasible to train an end-to-end abstractive model given the memory constraints of current hardware.
Hence, first step is to coarsely select a subset of the input using extractive summarization.
Then, the second stage is to involve the training of an abstractive model that generates the Wikipedia text while conditioning on this extraction.
- This two-stage process is inspired by by how humans might summarize multiple long documents: First highlight pertinent information, then conditionally generate the summary based on the highlights.
- The extractive stage (first step) is to use some conventional methods. They are mainly based on word frequencies, unigram or bigram, etc.
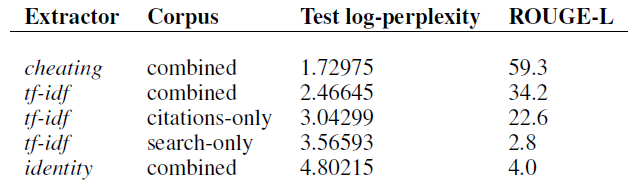
- There is a significant gap between tf-idf and the cheating extractor. But authors decide to keep using tf-idf and leave it as future work.
- (Authors try to use different methods for the extractive stage but without any new research on the extractive stage, thus I don’t mention them here.)
2. Abstractive Model
- Texts are retrieved from multiple documents in the extractive stage.
- Then, the texts are first tokenized as in GNMT, and truncated based on the input length L.



- The abstractive model W is to learn to write articles ai:
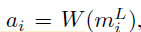
- which is a sequence transduction problem from very long input sequences (up to L = 11000) to medium output sequences (typically less than 500).
2.1. Baseline
- seq2seq-att: A baseline is the the standard LSTM encoder-decoder with attention (Attention Decoder), which is trained to optimize the maximum-likelihood objective:
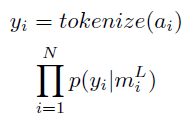
- It has a hidden size of 128 with 2 layers.
- T-ED: A stronger, more recent baseline that we use is the non-recurrent Transformer model, which also has symmetric encoder and decoder modules (T-ED).
2.2. Transformer Decoder (T-D)
- A simple but effective modification is made to T-ED for long sequences that drops the encoder module (almost reducing model parameters by half for a given hyper-parameter set), combines the input and output sequences into a single ”sentence” and is trained as a standard language model.
- That is, a sequence-transduction example is converted from:
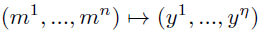
- into the sentence:
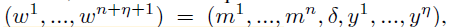
- where δ is a special separator token and a model is trained to predict the next word given the previous ones:
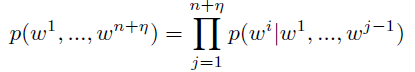
- Since the model is forced to predict the next token in the input, m, as well as y, error signals are propagated from both input and output time-steps during training.
Because of the self-attention of the Transformer, when generating the next token, attention from both m and y are considered.
- (Please feel free to read Transformer if interested.)
2.3. Transformer Decoder with Memory-Compressed Attention (T-DMCA)
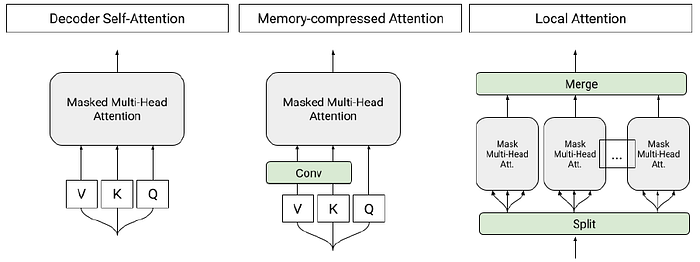
- Left, attention in Transformer: the attention is a function of a query (Q) and set of key (K) and value (V) pairs. To handle longer sequences, the multi-head self-attention of the Transformer is modified to reduce memory usage by limiting the dot products between Q and K in:
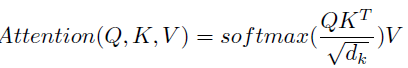
- Right, Local attention: Sequence tokens are divided into blocks of similar length and attention is performed in each block independently. Blocks of 256 tokens are chosen.
- Memory-Compressed Attention: After projecting the tokens into the query, key, and value embeddings, the number of keys and values are reduced by using a strided convolution. In the experiments, convolution kernels of size 3 with stride 3 are used. The memory-compressed attention layers are able to exchange information globally on the entire sequence.
3. Experimental Results

- By using the T-DMCA modifications, models were able to train up to L=11000 and continued to see improvements in performance.
- It is also found that MoE-layer helped performance by adding model capacity at high L, for example dropping log-perplexity from 2.05 to 1.93 at L=11000 with 128 experts.
- The best model attempted uses 256 experts at L=7500 (It was unable to use 256 experts with L=11000 due to memory constraints) and achieves a perplexity of 1.90.
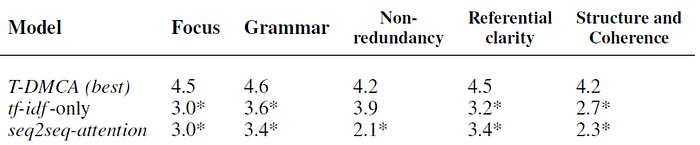
- Five different dimensions are assessed: grammaticality, non-redundancy, referential clarity, focus, and structure/coherence.
- The T-DMCA model does statistically significantly better on all dimensions.

- T-DMCA model offers a respectable alternative to the Wikipedia version and is more succinct, while mentioning key facts, such as where the law firm was located, when and how it was formed, and the rise and fall of the firm.
Since Transformer is originally used for machine translation, it consists of encoder and decoder. T-DMCA is proposed in which the Transformer’s encoder is removed.
Reference
[2018 ICLR] [T-DMCA]
Generating Wikipedia by Summarizing Long Sequences
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
