Brief Review — VirTex: Learning Visual Representations from Textual Annotations
VirTex, Jointly Train a ConvNet & Transformers From Scratch

VirTex: Learning Visual Representations from Textual Annotations,
VirTex, by University of Michigan
2021 CVPR, Over 190 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, VLM
- VirTex is proposed, a pretraining approach using semantically dense captions to learn visual representations.
- The network is trained from scratch on COCO Captions, and transfer to downstream recognition tasks including image classification, object detection, and instance segmentation.
Outline
- Motivations: Dense Semantic Density in Captions
- VirTex
- Results
1. Motivations: Dense Semantic Density in Captions

- Contrastive self-supervised learning methods provide a semantically sparse learning signal, encouraging different transforms of an image to have similar features.
- Image classification pairs an image with a single semantic concept, providing moderate semantic density.
- Multi-label classification, object detection, and instance segmentation increase semantic density by labeling and localizing multiple objects.
- Captions describe multiple objects, their attributes, relationships, and actions, giving a semantically dense learning signal.
In this work, authors aim to leverage this semantic density of captions to learn visual representations in a data-efficient manner.
2. VirTex

2.1. Overall Framework
- The model has two components: a visual backbone and a textual head.
- The visual backbone extracts visual features from an input image I.
- The textual head accepts these features and predicts a caption C = (c0, c1, …, cT, cT+1) token by token, where c0=[SOS] and cT+1=[EOS] are fixed special tokens indicating the start and end of sentence.
- The textual head performs bidirectional captioning (bicaptioning): it comprises a forward model that predicts tokens left-to-right, and a backward model that predicts right-to-left.
- All model components are randomly initialized, and jointly trained to maximize the log-likelihood of the correct caption tokens:

- where θ, φf, and φb are the parameters of the visual backbone, forward, and backward models respectively.
After training, the textual head is discarded and the visual backbone is transferred to downstream visual recognition tasks.
2.2. Texture Head
- The textual head comprises two identical language models which predict captions in forward and backward directions respectively.
- Transformer is used.
- After the last Transformer layer, a linear layer is applied to each vector to predict unnormalized log-probabilities over the token vocabulary.
The directional model is used for predicting tokens one by one.
- While Masked Language Models (MLMs) used in BERT is not good, it is found that it converges more slowly than directional models. It is noted that MLMs have poor sample efficiency, as they only predict a subset of tokens for each caption, while directional models predict all tokens.
2.3. Visual Backbone
- Standard ResNet-50 is used as the visual backbone. It accepts a 224×224 image and produces a 7×7 grid of 2048-dimensional features after the final convolutional layer.
- During pretraining, a linear projection layer is applied to the visual features before passing them to the textual head to facilitate decoder attention over visual features. This projection layer is not used in downstream tasks.
3. Results
3.1. Downstream VOC07 and ImageNet-1k

- Left: Annotation costs in terms of worker hours.
VirTex outperforms all methods, and has the best performance vs. cost tradeoff, indicating that learning visual features using captions is more cost-efficient than labels or masks.
- Right: 4 VirTex models using {10, 20, 50, 100}% of COCO Captions (118K images) and 7 ResNet-50 models using {1, 2, 5, 10, 20, 50, 100}% of ImageNet-1k (1.28M images).
VirTex-100% outperforms IN-sup-100% (mAP 88.7 vs 87.6), despite using 10× fewer images (118K vs. 1.28M).
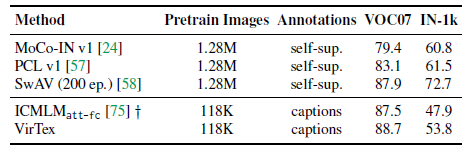
VirTex outperforms all methods, e.g.: ICMLM, MoCo, on VOC07, despite being trained with much fewer images.
3.2. Ablations
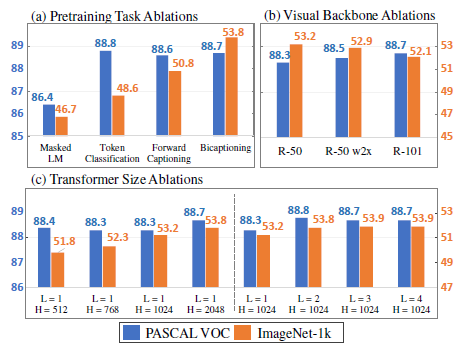
(a) Pretraining Tasks: Bicaptioning improves over weaker pretraining tasks — forward captioning, token classification and masked language modeling.
(b) Visual Backbone: Bigger visual backbones improve downstream performance — both, wider (R-50 w2×) and deeper (R-101).
(c) Transformer Size: Larger Transformers (wider and deeper) improve downstream performance. (L: Layers, H: Hidden Dimension Size)
3.3. Fine-tuning Tasks for Transfer
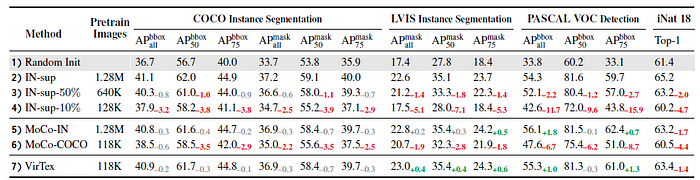
VirTex matches or exceeds ImageNet-supervised pretraining and MoCo-IN on all tasks (row 2,5 vs. 7) despite using 10× fewer pretraining images.
- Moreover, VirTex significantly outperforms methods that use similar, or more pretraining images (row 3,4,6 vs. 7), indicating its superior data-efficiency.
- Among all tasks, VirTex shows significant improvements on LVIS.
3.4. Image Captioning

- Left: The goal is not to advance the state-of-the-art in image captioning, all models show modest performance, far from current state-of-the-art methods.
Right: The model attends to relevant image regions for making predictions, indicating that VirTex learns meaningful visual features with good semantic understanding.
Reference
[2021 CVPR] [VirTex]
VirTex: Learning Visual Representations from Textual Annotations
3.1. Visual/Vision/Video Language Model (VLM)
2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT] [OSCAR] 2021 [CLIP] [VinVL] [ALIGN] [VirTex] 2022 [FILIP] [Wukong]
