Review — BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Pretraining Using BERT, Fine-Tuning BERT for Downstream Tasks

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT, by Google AI Language
2019 NAACL, Over 31000 Citations (Sik-Ho Tsang @ Medium)
Language Model
- BERT, Bidirectional Encoder Representations from Transformers, is proposed, to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
- This pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
This is a kind of self-supervised learning that pretext task is the language model learning while specific tasks are downstream tasks with fine-tuning.
Outline
- BERT: Bidirectional Encoder Representations from Transformers
- Pretraining BERT
- Fine-Tuning BERT
- SOTA Comparison
- Ablation Study
1. BERT: Bidirectional Encoder Representations from Transformers
1.1. BERT Training Steps
- There are two steps in BERT framework: pre-training and fine-tuning.
- During pre-training, the model is trained on unlabeled data over different pre-training tasks.
- For fine-tuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks.
1.2. BERT Model Architecture

- BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on Transformer. The implementation is almost identical to the original one.
- The number of layers (i.e., Transformer blocks) is denoted as L, the hidden size is denoted as H, and the number of self-attention heads as A.3
- Two model sizes are evaluated:
- BERTBASE (L=12, H=768, A=12, Total Parameters=110M), which has the same model size as OpenAI GPT for comparison purposes. BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
- BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M).
1.3. Input Representation

- To make BERT handle a variety of down-stream tasks, the input representation is able to unambiguously represent both a single sentence and a pair of sentences (e.g., <Question, Answer>) in one token sequence.
- WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary, is used.
- The first token of every sequence is always a special classification token ([CLS]).
- A special token ([SEP]) is used for separation.
For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings. A visualization of this construction is as shown above.
2. Pretraining BERT
2.1. Masked LM (MLM)
- Some percentage of the input tokens is masked at random, and then those masked tokens are to be predicted.
- 15% of all WordPiece tokens are masked at random in each sequence.
- Only the masked words are predicted rather than reconstructing the entire input.
- If the i-th token is chosen, the i-th token is replaced with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time. Then, Ti will be used to predict the original token with cross entropy loss.
2.2. Next Sentence Prediction (NSP)
- Downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling. A binarized next sentence prediction task is pretrained that can be trivially generated from any monolingual corpus.
- Specifically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext).
2.3. Pretraining Dataset
- For the pre-training corpus, the BooksCorpus (800M words) (Zhu et al., 2015) and English Wikipedia (2,500M words) are used.
- For Wikipedia, only the text passages are extracted and lists, tables, and headers are ignored.
3. Fine-Tuning BERT

For each task, the task-specific inputs and outputs are simply plugged into BERT and all the parameters are fine-tuned end-to-end.
- At the input, sentence A and sentence B from pre-training are analogous to (1) sentence pairs in paraphrasing, (2) hypothesis-premise pairs in entailment, (3) question-passage pairs in question answering, and (4) a degenerate text-Ø pair in text classification or sequence tagging.
- At the output, the token representations are fed into an output layer for token-level tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.
- Compared to pre-training, fine-tuning is relatively inexpensive. All of the results in the paper can be replicated in at most 1 hour on a single Cloud TPU, or a few hours on a GPU.
4. SOTA Comparison
4.1. GLUE

- The only new parameters introduced during fine-tuning are classification layer weights W, where K is the number of labels. A standard classification loss with C and W is computed, i.e., log(softmax(CW^T)).
Both BERTBASE and BERTLARGE outperform all systems on all tasks by a substantial margin, obtaining 4.5% and 7.0% respective average accuracy improvement over the prior state of the art.
- Note that BERTBASE and OpenAI GPT are nearly identical in terms of model architecture apart from the attention masking.
- For the largest and most widely reported GLUE task, MNLI, BERT obtains a 4.6% absolute accuracy improvement. On the official GLUE leaderboard, BERTLARGE obtains a score of 80.5, compared to OpenAI GPT, which obtains 72.8 as of the date of writing.
4.2. SQuAD 1.1.
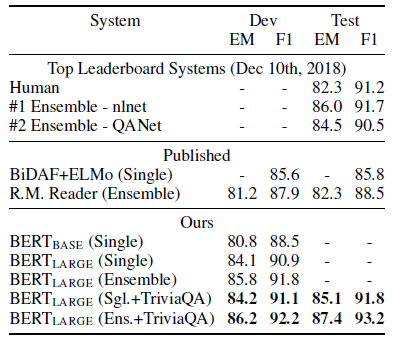
- The Stanford Question Answering Dataset (SQuAD v1.1) is a collection of 100k crowdsourced question/answer pairs.
- The input question and passage are represented as a single packed sequence, with the question using the A embedding and the passage using the B embedding.
- Only a start vector S and an end vector E are introduced during fine-tuning.
- The probability of word i being the start of the answer span is computed as a dot product between Ti and S followed by a softmax over all of the words in the paragraph:
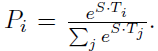
- Similar for the end of the answer span.
- The score of a candidate span from position i to position j is defined as:

- The maximum scoring span where j≥i is used as a prediction.
The best BERT outperforms the top leaderboard system by +1.5 F1 in ensembling and +1.3 F1 as a single system. In fact, the single BERT model outperforms the top ensemble system in terms of F1 score.
4.3. SQuAD 2.0
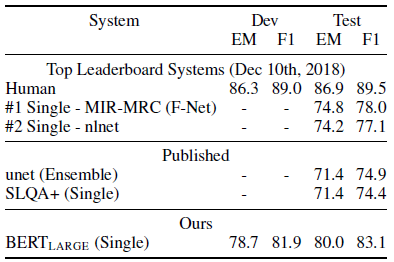
- The SQuAD 2.0 task extends the SQuAD 1.1 problem definition by allowing for the possibility that no short answer exists in the provided paragraph, making the problem more realistic
A +5.1 F1 improvement is observed over the previous best system.
4.4. SWAG
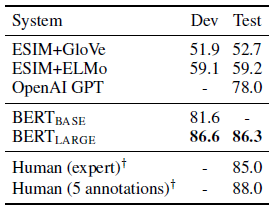
- The Situations With Adversarial Generations (SWAG) dataset contains 113k sentence-pair completion examples that evaluate grounded common-sense inference.
- Given a sentence, the task is to choose the most plausible continuation among four choices.
- When fine-tuning on the SWAG dataset, four input sequences are constructed, each containing the concatenation of the given sentence (sentence A) and a possible continuation (sentence B).
BERTLARGE outperforms the authors’ baseline ESIM+ELMo system by +27.1% and OpenAI GPT by 8.3%.
5. Ablation Study
5.1. Effect of Pre-Training Tasks

- “No NSP” is trained without the next sentence prediction task.
- “LTR & No NSP” is trained as a left-to-right LM without the next sentence prediction, like OpenAI GPT.
- “+ BiLSTM” adds a randomly initialized BiLSTM on top of the “LTR + No NSP” model during fine-tuning.
- Removing NSP hurts performance significantly on QNLI, MNLI, and SQuAD 1.1.
- The LTR model performs worse than the MLM model on all tasks, with large drops on MRPC and SQuAD.
5.2. Effect of Model Size
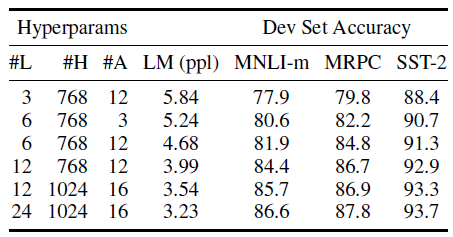
- Larger models lead to a strict accuracy improvement across all four datasets, even for MRPC which only has 3,600 labeled training examples, and is substantially different from the pre-training tasks.
- This is the first work to demonstrate convincingly that scaling to extreme model sizes also leads to large improvements on very small scale tasks, provided that the model has been sufficiently pre-trained.
5.3. Feature-based Approach with BERT
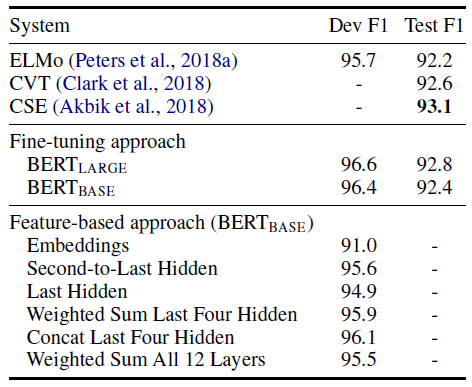
- All of the BERT results presented so far have used the fine-tuning approach, where a simple classification layer is added to the pre-trained model, and all parameters are jointly fine-tuned on a downstream task.
- However, the feature-based approach, where fixed features are extracted from the pretrained model, is evaluated here. Two reasons are:
- First, not all tasks can be easily represented by a Transformer encoder architecture.
- Second, major computational benefits can be pre-computed.
- The feature-based approach is applied by extracting the activations from one or more layers without fine-tuning any parameters of BERT.
- These contextual embeddings are used as input to a randomly initialized two-layer 768-dimensional BiLSTM before the classification layer.
- The best performing method concatenates the token representations from the top four hidden layers of the pre-trained Transformer, which is only 0.3 F1 behind fine-tuning the entire model.
- This demonstrates that BERT is effective for both finetuning and feature-based approaches.
Reference
[2019 NAACL] [BERT]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [BERT]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
