Review — GFNet: Global Filter Networks for Image Classification
GFNet, Included discrete Fourier transform (DFT) into Network
Global Filter Networks for Image Classification,
GFNet, by Tsinghua University,
2021 NeurIPS, Over 90 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, Transformer
- The complexity of self-attention and MLP grows quadratically as the image size increases, which makes these models hard to scale up.
- Global Filter Network (GFNet), is proposed that learns long-term spatial dependencies in the frequency domain with log-linear complexity.
- GFNet replaces the self-attention layer in ViTs with three key operations: a 2D discrete Fourier transform, an element-wise multiplication between frequency-domain features and learnable global filters, and a 2D inverse Fourier transform.
Outline
- Discrete Fourier Transform (DFT)
- Global Filter Network (GFNet)
- Results
1. Discrete Fourier Transform (DFT)
1.1. 1D DFT
- Given a sequence of N complex numbers x[n], 0≤n≤N-1, the 1D DFT converts the sequence into the frequency domain by:

- where j is the imaginary unit and WN=e^(-j(2π/N)).
- It is also worth noting that DFT is a one-to-one transformation. Given the DFT X[k], the original signal x[n] can be recovered by the inverse DFT (IDFT):

- DFT is widely used in modern signal processing algorithms for mainly two reasons: (1) the input and output of DFT are both discrete thus can be easily processed by computers; (2) there exist efficient algorithms for computing the DFT, such as Fast Fourier Transform (FFT).
1.2. 2D DFT
- The DFT described above can be extended to 2D signals.

- where the 2D DFT can be viewed as performing 1D DFT on the two dimensions alternatively.
2. Global Filter Network (GFNet)

2.1. Overall Architecture
- The model takes as an input H×W non-overlapping patches and projects the flattened patches into L=HW tokens with dimension D.
- The basic building block of GFNet consists of:
- A global filter layer that can exchange spatial information efficiently (O(L log L));
- A feedforward network (FFN) as in ViT and DeiT.
- The output tokens of the last block are fed into a global average pooling layer followed by a linear classifier.
2.2. Global Filter Layer
- Given the tokens x, 2D FFT along the spatial dimensions is performed to convert x to the frequency domain:
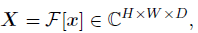
- where F[.] denotes the 2D FFT. Note that X is a complex tensor and represents the spectrum of x. The spectrum can then be modulated by multiplying a learnable filter K.
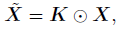
- where ⨀ is the element-wise multiplication (also known as the Hadamard product). The filter K is called the global filter since it has the same dimension with X.
- The inverse FFT is adopted to transform the modulated spectrum ~X back to the spatial domain and update the tokens:
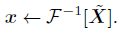
- To reduce the redundant computation, we can take only the half of the values in the X but preserve the full information at the same time:
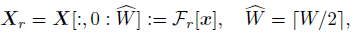
- Both the FFT and the IFFT have no learnable parameters and can process sequences with arbitrary length. The global filter K can be simply interpolated to K’ for different inputs.

- The proposed global filter is much more efficient than self-attention and spatial MLP.
2.3. GFNet Variants
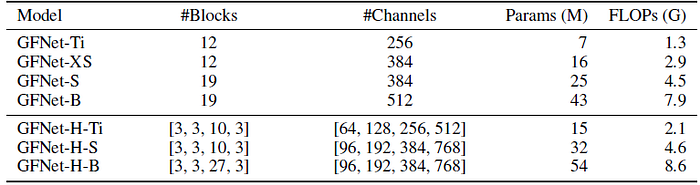
- Two kinds of variants of GFNet: Transformer-style models with a fixed number of tokens in each block and CNN-style hierarchical models with gradually downsampled tokens.
- For Transformer-style models, a 12-layer model (GFNet-XS) is begun with a similar architecture with DeiT-S and ResMLP-12. Then, 3 variants of the model (GFNet-Ti, GFNet-S and GFNet-B) are obtained by simply adjusting the depth and embedding dimension, which have similar computational costs with ResNet-18, 50 and 101.
- For hierarchical models, three models (GFNet-H-Ti, GFNet-H-S and GFNet-H-B) are designed that have these three levels of complexity following the design of PVT.
3. Results
3.1. ImageNet

GFNet can clearly outperform recent MLP-like models such as ResMLP and gMLP, and show similar performance to DeiT.
- Specifically, GFNet-XS outperforms ResMLP-12 by 2.0% while having slightly fewer FLOPs. GFNet-S also achieves better top-1 accuracy compared to gMLP-S and DeiT-S.
- The proposed tiny model is significantly better compared to both DeiT-Ti (+2.4%) and gMLP-Ti (+2.6%) with the similar level of complexity.
GFNet can easily adapt to higher resolution (384) with only 30 epoch finetuning and achieve better performance.
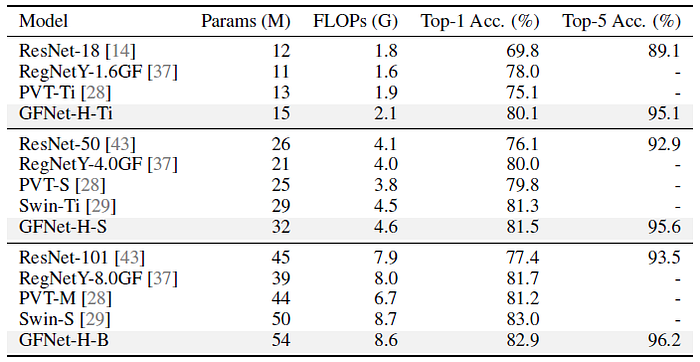
GFNet-H models show significantly better performance than ResNet, RegNet and PVT, and achieve similar performance with Swin while having a much simpler and more generic design.
3.2. Transfer Learning
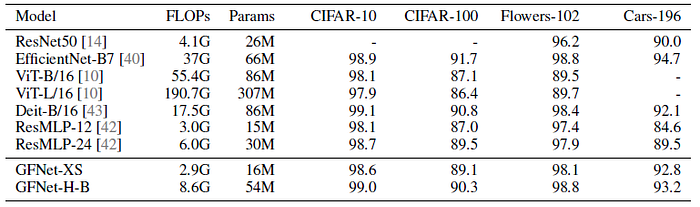
The proposed models generally work well on downstream datasets. GFNet models outperform ResMLP models by a large margin and achieve very competitive performance with state-of-the-art EfficientNet-B7.
3.3. Analysis and visualization
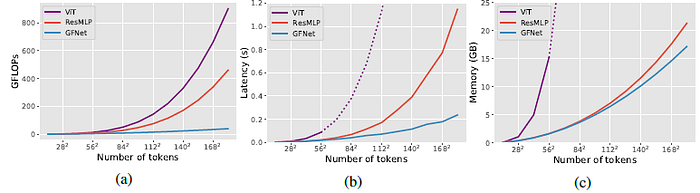
The advantage of the proposed architecture becomes larger as the resolution increases, which strongly shows the potential of the proposed model in vision tasks requiring high-resolution feature maps.
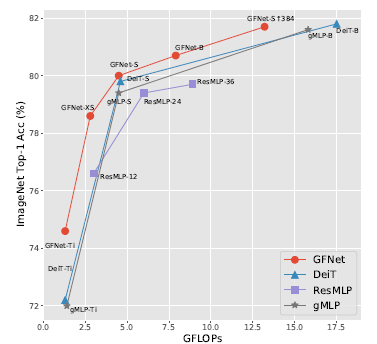
GFNet achieves the best trade-off among all kinds of models.
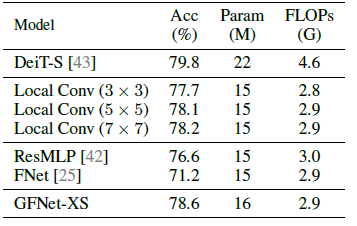
GFNet outperforms all baseline methods except DeiT-S that has 64% higher FLOPs.

GFNet enjoys both favorable robustness and generalization ability.

The learned global filters have more clear patterns in the frequency domain. Interestingly, the filters in the last layer particularly focus on the low-frequency component.
References
[2021 NeurIPS] [GFNet]
Global Filter Networks for Image Classification
[GitHub] https://github.com/raoyongming/GFNet
1.1. Image Classification
1989–2021 … [GFNet] … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer] [Sparse MLP] [MViTv2] [S²-MLP] 2023 [Vision Permutator (ViP)]
