Review — Micro-Batch Training with Batch-Channel Normalization and Weight Standardization
Weight Standardization (WS) and Batch-Channel Normalization (BCN) are Proposed
Micro-Batch Training with Batch-Channel Normalization and Weight Standardization,
WS, BCN, by Johns Hopkins University
2020 arXiv v2, Over 40 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Group Normalization (GN), Weight Normalization (WN),
- Weight Standardization (WS) standardizes the weights in convolutional layers.
- Batch-Channel Normalization (BCN) combines batch and channel normalizations and leverages estimated statistics of the activations in convolutional layers.
Outline
- Weight Standardization (WS)
- Batch-Channel Normalization (BCN)
- Experimental Results
1. Weight Standardization (WS)

1.1. WS
- Consider a standard convolutional layer with its bias term set to 0:

- In Weight Standardization (WS), instead of directly optimizing the loss L on the original weights ^W, the weights ^W are reparameterized as a function of W, i.e. ^W=WS(W).

- where:

- The loss L is optimized on W by SGD:

- (.W is the intermediate symbol used in the paper.)
1.2. Comparing WS with WN and CWN


- (Please feel free to read WN and CWN for more details if interested.)
- To compare with WN and CWN, WS considers the weights for only one of the output channel and reformulate the corresponding weights output as:

- And the learnable length g is also removed.
2. Batch-Channel Normalization (BCN)
- Batch Normalization is estimated across batch. When batch size is small, BN harms the training.
- Batch-Channel Normalization (BCN) is proposed, which can be used for micro-batch training.

- ^μc and ^σc are not updated by the gradients computed from the loss function; instead, they are updated towards more accurate estimates of those statistics (Step 3 and Step 4).
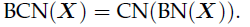
- BCN has a channel normalization following the estimate-based normalization. This makes the previously unstable estimate-based normalization stable.
- (Some details need to be confirmed by reading the codes.)
3. Experimental Results
3.1. Image Classification

GN+WS can be used together to improve the top-1 accuracy on ImageNet.
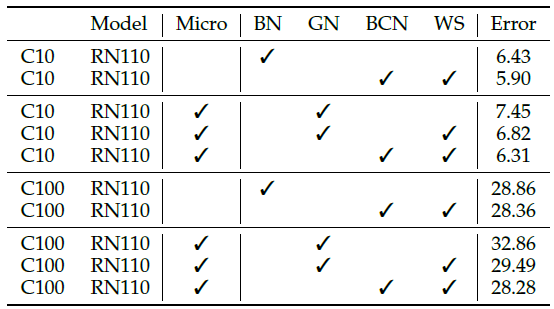
While GN+WS has good performance, BCN+WS is even better.
3.2. Object Detection and Instance Segmentation

Similar trends are observed in Object Detection and Instance Segmentation on MS COCO Val 2017.
Later, another arXiv paper uses WS on BYOL. Please stay tuned.
References
[2020 arXiv v2] [WS, BCN]
Micro-Batch Training with Batch-Channel Normalization and Weight Standardization
[GitHub] https://github.com/joe-siyuan-qiao/WeightStandardization
Image Classification
2020 … [WS, BCN] … 2021 [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1] [CvT] [HaloNet] [TNT] [CoAtNet] [Focal Transformer] [TResNet] [CPVT] 2022 [ConvNeXt]
