Review — TResNet: High Performance GPU-Dedicated Architecture
TResNet, Refinements and Changes From ResNet, Outperforms EfficientNet
TResNet: High Performance GPU-Dedicated Architecture
TResNet, by DAMO Academy, Alibaba Group
2021 WACV, Over 90 Citations (Sik-Ho Tsang @ Medium)
Image Classification, CNN, Residual Network, ResNet
- A series of architecture modifications are introduced that aim to boost neural networks’ accuracy, while retaining their GPU training and inference efficiency.
- First, the bottlenecks induced by FLOPs oriented optimizations are discussed. Then, alternative designs are suggested that better utilize GPU structure and assets. Finally, a new family of GPU-dedicated models, called TResNet, is introduced.
Outline
- Motivation
- TResNet: Refinements and Changes From ResNet
- Experimental Results
1. Motivation

- The above table compares ResNet50 to popular newer architectures, with similar ImageNet top-1 accuracy — ResNet50-D [11], ResNeXt50 [43], SEResNeXt50 (SENet+ResNeXt) [13], EfficientNet-B1 [36] and MixNet-L (MixConv) [37].
- The reduction of FLOPs and the usage of new tricks in modern networks, compared to ResNet50, is not translated to improvement in GPU throughput.
- Modern networks like EfficientNet, ResNeXt and MixNet (MixConv) do extensive usage of depthwise and 1×1 convolutions, that provide significantly fewer FLOPs than 3×3 convolutions. However, GPUs are usually limited by memory access cost and not by number of computations, especially for low-FLOPs layers.
- Modern networks like ResNeXt and MixNet (MixConv) do extensive usage of multi-path. For training, this creates lots of activation maps that need to be stored for backward propagation, which reduces the maximal possible batch size, thus hurting the GPU throughput.
TResNet is designed to aim at high accuracy while maintaining high GPU utilization.
2. TResNet: Refinements and Changes From ResNet
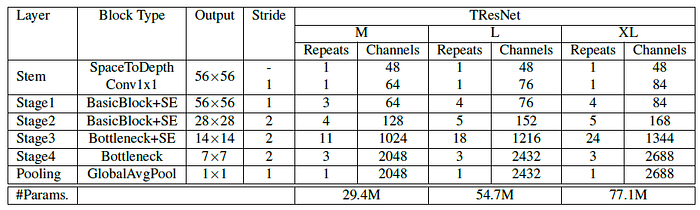
- It contains three variants, TResNet-M, TResNet-L and TResNet-XL, that vary only in their depth and the number of channels.
- TResNet has the following refinements and changes compared to plain ResNet50 design:
- SpaceToDepth Stem
- Anti-Alias Downsampling
- In-Place Activated BatchNorm
- Novel Block-type Selection
- Optimized SE Layers
2.1. SpaceToDepth Stem

- ResNet50 stem is comprised of a stride-2 conv7×7 followed by a max pooling layer.
- ResNet-D replaces conv7×7 by three conv3×3 layers. This design did improve accuracy, but at a cost of lowering the training throughput.
- Here, a dedicated SpaceToDepth transformation layer [33] is used, that rearranges blocks of spatial data into depth.
- The SpaceToDepth layer is followed by simple convolution, to match the number of wanted channels.
2.2. Anti-Alias Downsampling (AA)

- The stride-2 convolutions are replaced by stride-1 convolutions followed by a 3×3 blur kernel filter with stride 2.
2.3. In-Place Activated BatchNorm (Inplace-ABN)
- All BatchNorm+ReLU layers are replaced by Inplace-ABN [32] layers, which implements BatchNorm with activation as a single inplace operation, allowing to reduce significantly the memory required for training deep networks, with only a small increase in the computational cost.
- And Leaky-ReLU is used instead of ResNet50’s plain ReLU.
2.4. Novel Block-Type Selection
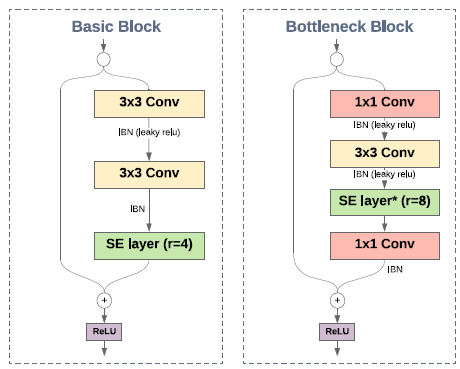
- Bottleneck layers have higher GPU usage than BasicBlock layers, but usually give better accuracy. However, BasicBlock layers have larger receptive field, so they might be more suited to be placed at the early stages of a network.
- Since BasicBlock layers have a larger receptive field, they are placed at the first two stages of the network, and Bottleneck layers at the last two stages.
- The number of initial channels, and the number of residual blocks in the 3rd stage are also modified, similarly to [10] and [36].
- Details are tabulated as above.
2.5. Optimized SE Layers
- SE layers only are placed in the first three stages of the network, to gain the maximal speed-accuracy benefit.
- For Bottleneck units, the SE module is added after the conv3×3 operation, with a reduction factor of 8 (r=8).
- For BasicBlock units, SE module is added just before the residual sum, with a reduction factor of 4 (r=4).
2.6. Code Optimizations
- Other than architecture refinements, code optimizations are also used.
- JIT compilation enables, at execution time, to dynamically compile a high-level code into highly-efficient, optimized machine code. This is in contrast to the default Pythonic option of running a code dynamically, via an interpreter. For the AA and SpaceToDepth modules, it is found that JIT compilation reduces the GPU cost by almost a factor of two.
- Inplace Operations change directly the content of a given tensor, without making a copy, prevent creation of unneeded activation maps for backward propagation. Inplace operations are used as as much as possible. By such, TResNet-M maximal batch size is almost twice of ResNet50–512,
- Fast Global Average Pooling, a simple dedicated implementation of GAP, with optimized code for the specific case of (1,1) spatial output, can be up to 5 times faster than the boilerplate implementation on GPU.
- Deployment Optimizations can be used for enhancing (frozen) model inference speed during deployment. For example, BatchNorm layers can be fully absorbed into the convolution layers before them. But TResNet AVOIDS doing inference-tailored optimizations.
3. Experimental Results
3.1. ImageNet

TResNet-M, which has similar GPU throughput to ResNet50, has significantly higher validation accuracy on ImageNet (+1.8%).
- Training TResNet-M and ResNet50 models takes less than 24 hours on an 8×V100 GPU machine, showing that the training scheme is also efficient and economical.
- Another strength of the TResNet models is the ability to work with significantly larger batch sizes than other models.
3.2. Ablation Study
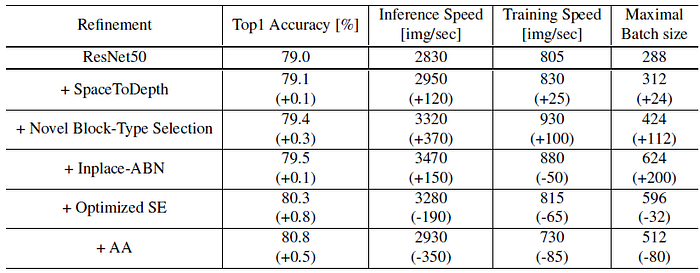
- While the GPU throughput improvement is expected, the fact that also the accuracy improves (marginally) when replacing the ResNet stem cell by a ”cheaper” SpaceToDepth unit is somewhat surprising.
- Block type selection provides significant improvements to all indices.
- Inplace-ABN significantly increases the possible batch size, by 200 images. The impact of Inplace-ABN is mixed: while the inference speed improved, the training speed was somewhat reduced.
- Optimized SE + Anti-Aliasing layers significantly improve the ImageNet top-1 accuracy, with a price of reducing the model GPU throughput.
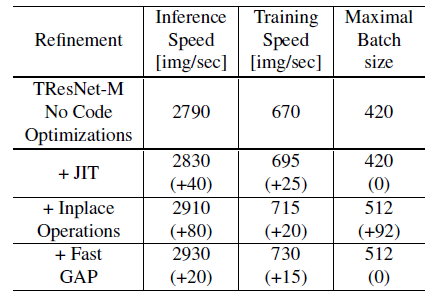
Among the optimizations, dedicated inplace operations give the greatest boost — not only it improves the GPU throughput, but it also significantly increases the maximal possible batch size, since it avoids the creation of unneeded activation maps for backward propagation.
3.3. High-Resolution Fine-Tuning
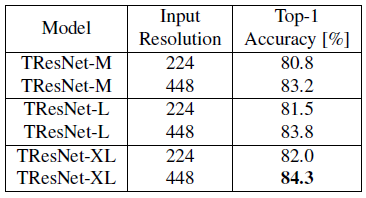
- 224 ImageNet-pre-trained TResNet models are used as a starting point, and have a short 10 epochs fine-tuning to input resolution of 448.
TResNet models scale well to high resolutions. Even TResNet-M, which is a relatively small and compact model, can achieve top-1 accuracy of 83.2% on ImageNet with high-resolution input.
3.4. Comparison to EfficientNet Models
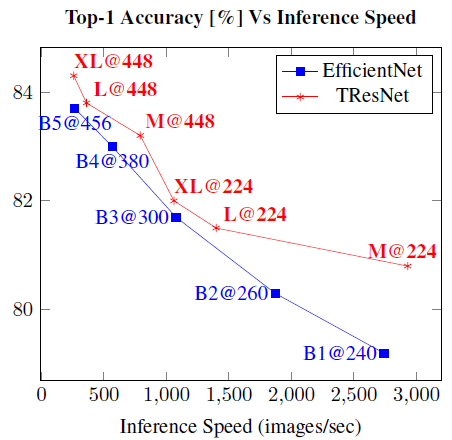
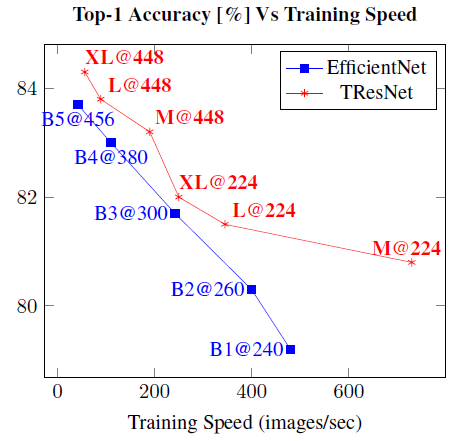
- All along the top-1 accuracy curve, TResNet models give better inference-speed-accuracy and training-speed-accuracy tradeoff than EfficientNet models.
3.5. Transfer Learning
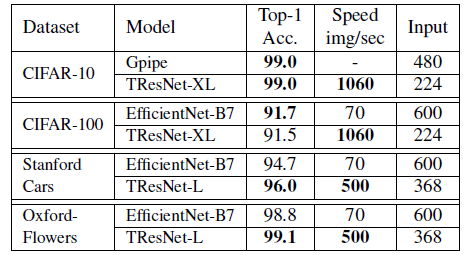
- ImageNet pre-trained checkpoints are used, and fine-tuned the models for 80 epochs.
TResNet surpasses or matches the state-of-the-art accuracy on 3 of the 4 datasets, with 8–15× faster GPU inference speed. Note that all TResNet’s results are from single-crop single-model evaluation.

TResNet-based solution significantly outperforms previous top solution for MSCOCO multi-label dataset, increasing the known SOTA by a large margin, from 83.7 mAP to 86.4 mAP.

Reference
[2021 WACV] [TResNet]
TResNet: High Performance GPU-Dedicated Architecture
Image Classification
1989 … 2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1] [CvT] [HaloNet] [TNT] [CoAtNet] [Focal Transformer] [TResNet]
