Review: MT-DNN (NLP)
Multi-Task Learning for Multi-Task Deep Neural Network
Multi-Task Deep Neural Networks for Natural Language Understanding
MT-DNN, by Microsoft Research, and Microsoft Dynamics 365 AI
2019 ACL, Over 700 Citations (Sik-Ho Tsang @ Medium)
Language Model, Natural Language Processing, NLP, BERT
- It is easier for a person who knows how to ski to learn skating than the one who does not.
- Multi-Task Learning (MTL) is inspired by human learning activities, applying onto BERT to further improve the performance.
Outline
- MT-DNN: Multi-Task Learning
- Experimental Results
1. MT-DNN: Multi-Task Learning

- The lower layers are shared across all tasks, while the top layers represent task-specific outputs.
- l1: The input X, which is a word sequence (either a sentence or a pair of sentences packed together) is first represented as a sequence of embedding vectors, one for each word, in l1.
- l2: Then, the transformer encoder captures the contextual information for each word via self-attention, and generates a sequence of contextual embeddings in l2. This is the shared semantic representation that is trained by the proposed multi-task objectives.
1.1. Lexicon Encoder (l1)
- The input X={x1, …, xm} is a sequence of tokens of length m.
- Following BERT, the first token x1 is always the [CLS] token. If X is packed by a sentence pair (X1, X2), the two sentences are separated with a special token [SEP].
The lexicon encoder maps X into a sequence of input embedding vectors, one for each token.
- (Please feel free to read BERT.)
1.2. Transformer Encoder (l2)
- A multilayer bidirectional Transformer encoder is used to map the input representation vectors (l1) into a sequence of contextual embedding vectors C.
But unlike BERT, MT-DNN learns the representation using multi-task objectives, in addition to pre-training.
1.3. Multi-Task Learning (MTL)
1.3.1. Classification
- For the classification tasks (i.e., single-sentence or pairwise text classification), cross-entropy loss is used as the objective:


- where 1(X, c) is the binary indicator (0 or 1) if class label c is the correct classification for X, and W_SST is the task-specific parameter matrix.
1.3.2. Text Similarity
- For the text similarity tasks, such as STS-B, where each sentence pair is annotated with a real-valued score y, mean squared error is used:

- where Sim() is the similarity score.
1.3.3. Relevance Ranking
- For the relevance ranking tasks, given a query Q, a list of candidate answers A is obtained which contains a positive example A+ that includes the correct answer, and |A|-1 negative examples.
- The negative log likelihood of the positive example given queries across the training data is minimized.
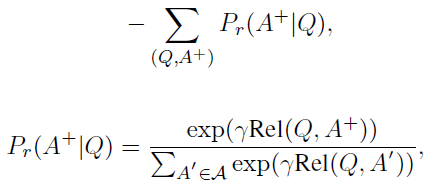
- where Rel(.) is relevance score. γ=1.
Given a mini batch, it can be batch of samples for different tasks.
For different tasks, different costs are minimized.
2. Experimental Results
2.1. GLUE

- MT-DNN: The pre-trained BERTLARGE is used to initialize its shared layers, the model is refined via MTL on all GLUE tasks, and the model is fine-tuned for each GLUE task using task-specific data.
MT-DNN outperforms all existing systems on all tasks, except WNLI, creating new state-of-the-art results on eight GLUE tasks and pushing the benchmark to 82.7%, which amounts to 2.2% absolution improvement over BERTLARGE.
- MTDNNno-fine-tune still outperforms BERTLARGE consistently among all tasks but CoLA.

- ST-DNN stands for Single-Task DNN. It uses the same model architecture as MT-DNN. But its shared layers are the pre-trained BERT model without being refined via MTL. ST-DNN is then fine-tuned for each GLUE task using task-specific data.
On all four tasks (MNLI, QQP, RTE and MRPC), ST-DNN outperforms BERT. ST-DNN significantly outperforms BERT demonstrates clearly the importance of problem formulation.
2.2. SNLI and SciTail
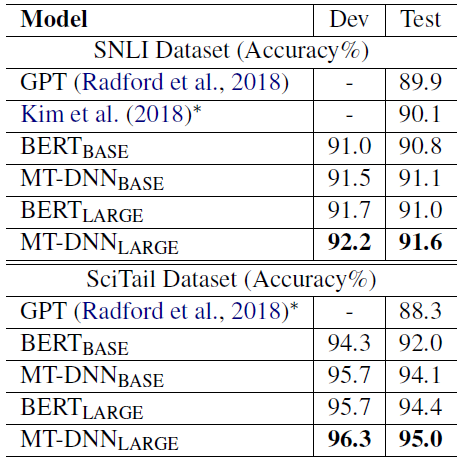
MT-DNNLARGE generates new state-of-the-art results on both datasets, pushing the benchmarks to 91.6% on SNLI (1.5% absolute improvement) and 95.0% on SciTail (6.7% absolute improvement), respectively.
Reference
[2019 ACL] [MT-DNN]
Multi-Task Deep Neural Networks for Natural Language Understanding
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [Transformer-XL] [BERT] [RoBERTa] [GPT-2] [DistilBERT] [MT-DNN]
