Review — S²-MLP: Spatial-Shift MLP Architecture for Vision
S²-MLP, Pure MLP Architecture, With Spatial Shift Operation
S²-MLP: Spatial-Shift MLP Architecture for Vision,
S²-MLP, by Baidu Research,
2022 WACV, Over 60 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT
- Prior MLP-Mixer uses pure MLP structures but it cannot achieve as outstanding performance as its CNN and ViT counterparts due to the use of token-mixing MLP.
- In this paper, Spatial-Shift MLP (S²-MLP), a novel pure MLP architecture, is proposed, without the use of token-mixing MLP.
- Instead, a spatial-shift operation is proposed for achieving the communication between patches. It has a local reception field and is spatial-agnostic. Meanwhile, it is parameter-free and efficient for computation.
Outline
- S²-MLP
- Results
1. S²-MLP

1.1. Overall Architecture
- An image, denoted by I of size W×H×3, is uniformly split into w×h patches, P.
- For each patch Pi, it is unfolded into a vector pi and projected into an embedding vector ei through a fully-connected layer followed by a layer normalization:

- Then, the embedding vectors go through N stacks of S²-MLP blocks of the same size and structure.
- Each spatial-shift block contains four fully-connected layers, two layer-normalization layers, two GELU layers, two skip-connections, and the proposed spatial-shift module.
- At the end, the feature maps output by last block are aggregated into a single feature vector through global average pooling, and fed into a fully-connected layer for predicting the label.
1.2. Spatial-Shift Module
- For the input tensor, it is split into g=4 thinner tensors along the channel dimension.
- For the first group of channels, T1, it is shifted along the wide dimension by +1. In parallel, the second group of channels, T2, is shifted along the wide dimension by −1. Similarly, T3 is shifted along the height dimension by +1 and T4 is shifted along the height dimension by −1:

After spatially shifting, each patch absorbs the visual content from its adjoining patches. The spatial-shift operation is parameter-free and makes the communication between different spatial locations feasible.
With N stacks of S²-MLP blocks, the global visual content will be gradually diffused to every patch.
1.3. Relationship with Depth-Wise Convolution
- In fact, the spatial-shift operation is equal to a depthwise convolution with a fixed and group-specific kernel weights:

1.4. Model Variants

- Due to limited computing resources, authors cannot afford the expensive cost of investigating the large and huge models.
- They have two settings only: wide and deep.
2. Results
2.1. ImageNet-1K

S²-MLP has obtained a comparable accuracy with respect to ViT.
- S²-MLP cannot achieve as high recognition accuracy as the state-of-the-art Transformer-based vision models such as CaiT, Swin-B and Nest-B.
Compared with MLP-Mixer and FF, S²-MLP-wide achieves a considerably higher accuracy.
Compared with ResMLP-36, S²-MLP-deep achieves higher accuracy.
2.2. CIFAR-10, CIFAR-100, & Car
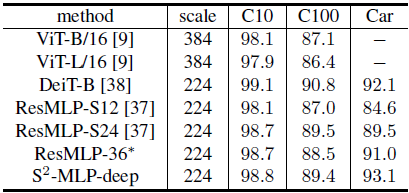
Using 224×224-scale images, S²-MLP-deep achieves better performance than ViT-B/16 and ViT-L/16 using 384×384-scale images.
Meanwhile, S²-MLP-deep achieves the comparable performance as DeiT-B with considerably fewer FLOPs.
On CIFAR100 and Car datasets, S²-MLP-deep considerably outperforms ResMLP-36.
2.3. Ablation Studies
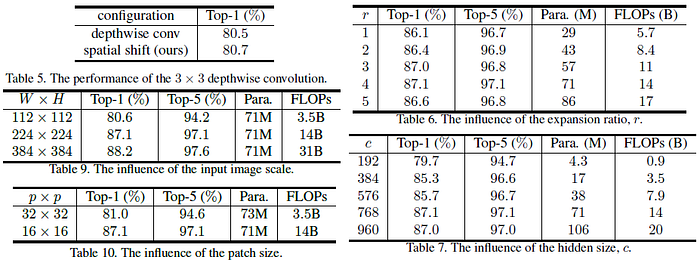
- Depthwise (Table 5): Interestingly, the proposed spatial-shift operation equivalent to 3×3 depthwise convolution, with pre-defined kernel achieves comparable accuracy as the 3×3 depthwise convolution with learned weights from the data.
- Expansion Ratio (Table 6): The top-1 accuracy increases from 86.1% to 87.0% as r increases from 1 to 3. Meanwhile, the number of parameters increases from 29M to 57M accordingly. But the accuracy saturates and even turns worse when r surpasses 3.
- Hidden Size (Table 7): The top-1 accuracy increases from 79.7% to 87.1% as the hidden size c increases from 192 and 768, and the number of parameters increases from 4.3M to 71M, and FLOPs increases from 0.9G to 20G. Meanwhile, the accuracy saturates when c surpasses 768.
- Input Scale (Table 9): When W×H increases from 112×112 to 336×336, the top-1 accuracy improves from 80.6% to 88.2%, the number of parameters keeps unchanged since the network does not change, and the FLOPs also increases from 3.5G to 31G.
- Patch Size (Table 10): When p increases from 16 to 32, it reduces FLOPs from 14B to 3.5B. But it also leads to that the top-1 accuracy drops from 87.1% to 81.0%.
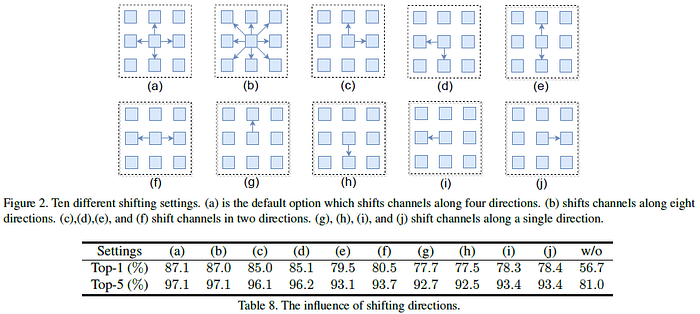
Shifting Directions (Table 8): Without shifting, the network performs poorly due to a lack of communications between patches.
- Meanwhile, comparing (e) with (f), the horizontal shifting is more useful than the vertical shifting.
- Comparing (c) with (e)/(f), it is observed that shifting in two dimensions (both horizontal and vertical) will be helpful than shifting in a single dimension (horizontal or vertical).
Moreover, comparing (a) and (b), we conclude that shifting along four directions is enough.
Many works investigates into MLP, attempting to replace Transformer.
Reference
[2022 WACV] [S²-MLP]
S²-MLP: Spatial-Shift MLP Architecture for Vision
1.1. Image Classification
1989 … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer] [Sparse MLP] [MViTv2] [S²-MLP]