Brief Review — Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
ALBEF, Propose Cross-Model Attention, & Momentum Distillation
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation,
ALBEF, by Salesforce Research,
2021 NeurIPS, Over 250 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, VTM, ViT, Transformer
- A contrastive loss is introduced to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which enables more grounded vision and language representation learning.
- To improve learning from noisy web data, momentum distillation, a self-training method, is proposed, which learns from pseudo-targets produced by a momentum model.
Outline
- ALBEF
- Momentum Distillation
- Results
1. ALBEF

1.1. Model Architecture
- ALBEF contains an image encoder, a text encoder, and a multimodal encoder.
- A 12-layer Vision Transformer, ViT-B/16 is used as the image encoder, which is pre-trained on ImageNet-1k. An input image I is encoded into a sequence of embeddings: {vcls, v1, …, vN}, where vcls is the embedding of the [CLS] token.
- A 6-layer Transformer is used for both the text encoder and the multimodal encoder. The text encoder is initialized using the first 6 layers of the BERTbase model, and the multimodal encoder is initialized using the last 6 layers of the BERTbase.
- The text encoder transforms an input text T into a sequence of embeddings {wcls, w1, …, wN}, which is fed to the multimodal encoder.
- The image features are fused with the text features through cross attention at each layer of the multimodal encoder.
1.2. Pretraining
- ALBEF with three objectives: image-text contrastive learning (ITC) on the unimodal encoders, masked language modeling (MLM) and image-text matching (ITM) on the multimodal encoder.
- ITM is improved with online contrastive hard negative mining.
1.2.1. Image-Text Contrastive Learning (ITC)
- ITC aims to learn better unimodal representations before fusion.
- It learns a similarity function s such that parallel image-text pairs have higher similarity scores:

- where gv and gw are linear transformations that map the [CLS] embeddings to normalized lower-dimensional (256-d) representations.
- Inspired by MoCo, two queues are maintained to store the most recent M image-text representations g’v, g’w, from the momentum unimodal encoders, for calculating the similarity score:

- For each image and text, the softmax-normalized image-to-text and text-to-image similarities are calculated as:

- where τ is a learnable temperature parameter.
- Let yi2t(I) and yt2i(T) denote the ground-truth one-hot similarity, where negative pairs have a probability of 0 and the positive pair has a probability of 1. The image-text contrastive loss is defined as the cross-entropy H between p and y:

1.2.2. Masked Language Modeling (MLM)
- MLM utilizes both the image and the contextual text to predict the masked words.
- Similar to BERT, the input tokens are randomly masked out with a probability of 15% and replace them with the special token [MASK]. MLM minimizes a cross-entropy loss:
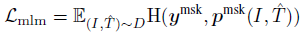
1.2.3. Image-Text Matching (ITM)
- ITM predicts whether a pair of image and text is positive (matched) or negative (not matched). The multimodal encoder’s output embedding of the [CLS] token is used as the joint representation of the image-text pair, and a fully-connected (FC) layer is appended and followed by softmax to predict a two-class probability pitm. The ITM loss is:
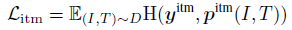
- A strategy to sample hard negatives for the ITM task with zero computational overhead. A negative image-text pair is hard if they share similar semantics but differ in fine-grained details.
- The contrastive similarity from the 3rd equation is used to find in-batch hard negatives.
- The total loss is:
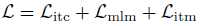
2. Momentum Distillation

- The image-text pairs used for pre-training are mostly collected from the web and they tend to be noisy. Positive pairs are usually weakly-correlated.
- Authors propose to learn from pseudo-targets generated by the momentum model. The momentum model is a continuously-evolving teacher which consists of exponential-moving-average versions of the unimodal and multimodal encoders.
- Specifically, for ITC, the image-text similarity is first computed using features from the momentum unimodal encoders as:
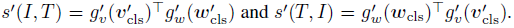
- Then, soft pseudo-targets qi2t and qt2i are computed by replacing s with s’.
- Finally, The ITCMoD loss is defined as:
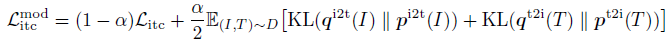
- Similarly, for MLM, let qmsk(I, ˆT) denote the momentum model’s prediction probability for the masked token, the MLMMoD loss is:
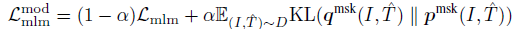
- MoD is also applied to the downstream tasks.
The final loss for each task is a weighted combination of the original task’s loss and the KL-divergence between the model’s prediction and the pseudo-targets.
3. Results
3.1. Pretraining Datasets
- The pre-training data is constructed using two web datasets (Conceptual Captions [4], SBU Captions [5]) and two in-domain datasets (COCO [41] and Visual Genome (VG) [42]). The total number of unique images is 4.0M, and the number of image-text pairs is 5.1M.
- To be scalable with larger-scale web data, the much noisier Conceptual 12M dataset is included, increasing the total number of images to 14.1M.
3.2. Some Downstream Details
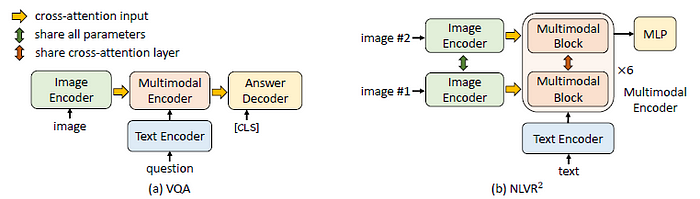
- For VQA, an auto-regressive decoder is appended to generate the answer given the image-question embeddings.
- For NLVR², the Transformer block within each layer of multimodal encoder is replicated to enable reasoning over two images.
3.3. Ablation
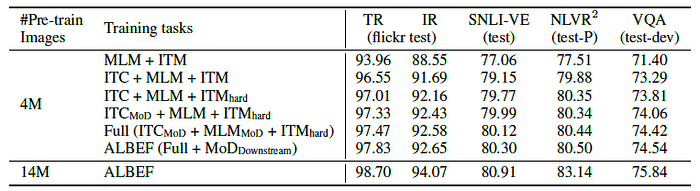
- Compared to the baseline pre-training tasks (MLM+ITM), adding ITC substantially improves the pre-trained model’s performance across all tasks.
- The proposed hard negative mining improves ITM by finding more informative training samples.
- Furthermore, adding momentum distillation improves learning for both ITC (row 4), MLM (row 5), and on all downstream tasks (row 6).
In the last row, ALBEF can effectively leverage more noisy web data to improve the pre-training performance.
3.4. Image-Text Retrieval
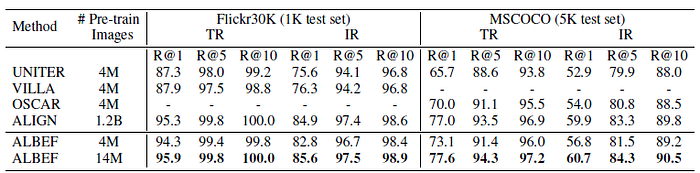
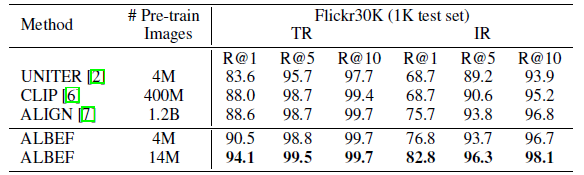
ALBEF achieves state-of-the-art performance, outperforming CLIP and ALIGN which are trained on orders of magnitude larger datasets.
3.5. VQA, NLVR, and VE

With 4M pre-training images, ALBEF already achieves state-of-the-art performance.
- With 14M pre-training images, ALBEF substantially outperforms existing methods such as VisualBERT, VL-BERT, LXMERT, including methods that additionally use object tags, i.e. OSCAR [3] or adversarial data augmentation [8].
3.6. Weakly-supervised Visual Grounding

ALBEF substantially outperforms existing methods [57, 58] (which use weaker text embeddings).
The Grad-CAM visualizations from ALBEF are highly correlated with where humans would look when making decisions.
Reference
[2021 NeurIPS] [ALBEF]
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
3.1. Visual/Vision/Video Language Model (VLM)
2017 [Visual Genome (VG)] 2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT] [OSCAR] 2021 [CLIP] [VinVL] [ALIGN] [VirTex] [ALBEF] 2022 [FILIP] [Wukong]
