Brief Review — MogaNet: Multi-order Gated Aggregation Network
MogaNet, Pure CNN Model

MogaNet: Multi-order Gated Aggregation Network
MogaNet, by Westlake University, Zhejiang University
2024 ICLR, Over 40 Citaitons (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++] [FastViT] [EfficientFormerV2] [MobileViTv2] [ConvNeXt V2] [SwiftFormer] [OpenCLIP] 2024 [FasterViT] [CAS-ViT] [TinySaver]
==== My Other Paper Readings Are Also Over Here ====
- MogaNet is proposed for discriminative visual representation learning in pure ConvNet-based models with favorable complexity-performance trade-offs.
- MogaNet encapsulates conceptually simple yet effective convolutions and gated aggregation into a compact module, where discriminative features are efficiently gathered and contextualized adaptively.
Outline
- MogaNet
- Results
1. MogaNet
1.1. Post-ViT Modern ConvNets

- Embedding stem downsamples the input X to downsampled features Z, to reduce redundancies and computational overload:

- Then, the feature flows to a stack of residual blocks. The network modules can be decoupled into two separate functional components, SMixer() (SA) and CMixer() (CA) for spatial-wise and channel-wise information propagation:

- where Norm() denotes a normalization. SMixer( ) can be various spatial operations (e.g., self-attention, convolution), while CMixer( ) is usually achieved by channel MLP with inverted bottleneck and expand ratio r.
- Within CA, a series of operations is performed to adaptively aggregate contextual information while suppressing trivial redundancies:

- where F () and G() are the aggregation and context branches. Reweighting is done by operation S(.).
In this paper, MogaNet is to design the appropriate function blocks using CNN.
1.2. Interaction Strength Analysis

Interaction strength against the order of interactions is used to analyze whether the ConvNet is good or not. The higher the better.
- Multi-order interactions between two input variables represent marginal contribution brought by collaborations among these two and other involved contextual variables, where the order indicates the number of contextual variables within the collaboration.
In brief, low-order interactions tend to encode common or widely-shared local texture, and the high-order ones are inclined to forcibly memorize the pattern of rare outliers. (There are numerous DNN explanability papers about this knowledge/topic.)
- As shown above, the extremely high-order interactions encoded in ViTs (e.g., DeiT), may stem from its adaptive global-range self-attention mechanism. However, the absence of locality priors still leaves ViTs lacking middle-order interactions.
- As for modern ConvNets (e.g., SLaK), despite the 51×51 kernel size, it still fails to encode enough expressive interactions.
- A naive combination of self-attention or convolutions can be intrinsically prone to the strong bias of global shape or local texture, infusing extreme-order interaction preference to models.
In MogaNet, authors aim to provide an architecture that can adaptively force the network to encode expressive interactions that would have otherwise been ignored inherently.
1.3. MogaNet Model Architecture
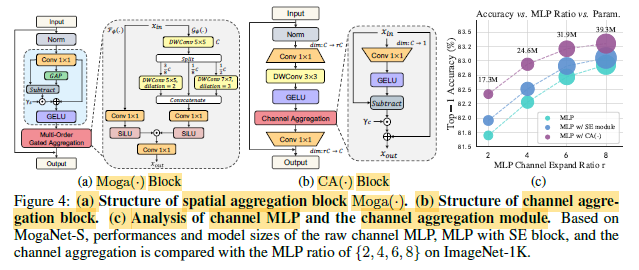
A spatial aggregation (SA) block as an instantiation of SMixer() to learn representations of multi-order interactions in a unified design, consists of two cascaded components:
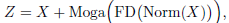
- where FD() indicates a feature decomposition module (FD) and Moga() denotes a multi-order gated aggregation module comprising the gating F () and context branch G().
Fine-grained local texture (low-order) and complex global shape (middle-order), are instantiated by Conv1×1() and GAP() respectively.
To force the network against its implicitly inclined interaction strengths, FD() is designed to adaptively exclude the trivial (overlooked) interactions:
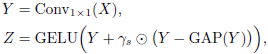
With Moga() being an ensemble of the depth-wise convolutions (DWConv).
- As in Figure 4 (a), in G(), three different DWConv layers with dilation ratios d ∈ {1, 2, 3} are used in parallel to capture low, middle, and high-order interactions.
- DW5×5,d=1 is first applied for low-order features. The output is split into 3 branches, with 1 with skip connection and 2 using DW5×5,d=2 and DW7×7,d=3 respectively. These 3 paths are concatenated back and goes through Conv1×1() again, and with SiLU as activation.
With also F() which has Conv1×1() and SiLU, Gated Aggregation is performed and Z becomes:
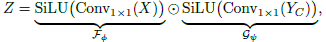
For CMixer(), a lightweight channel aggregation module CA() to adaptive reallocate channel-wise features in high-dimensional hidden spaces:
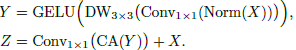
Concretely, CA() is implemented by a channel-reducing projection Wr and GELU to gather and reallocate channel-wise information:

1.4. MogaNet Model Family
- MogaNet is scaled for six model sizes (X-Tiny, Tiny, Small, Base, Large, and X-Large) via stacking the different number of spatial and channel aggregation blocks at each stage.
- The first embedding stem in MogaNet is designed as two stacked 3×3 convolution layers with the stride of 2 while adopting the single-layer version for embedding stems in other three stages.
2. Results

2.1. ImageNet
- ImageNet (Table 2): MogaNet-XT/T significantly outperforms existing lightweight architectures with a more efficient usage of parameters and FLOPs.
- ImageNet (Table 3): As for scaling-up models, MogaNet shows superior or comparable performances to SOTA architectures with similar parameters and computational costs.
2.2. Dense Task
- COCO Detection (Table 4): Detectors with MogaNet variants significantly outperform previous backbones.
- ADE20K Segmentation (Table 5): Semantic FPN with MogaNet-S consistently outperforms Swin-T and Uniformer-S by 6.2 and 1.1 points; UperNet with MogaNet-S/B/L improves ConvNeXt-T/S/B by 2.5/1.4/1.8 points. Using higher resolutions and IN-21K pre-training, MogaNet-XL achieves 54.0 SS mIoU, surpassing ConvNeXt-L and RepLKNet-31L by 0.3 and 1.6.
- COCO Human Pose Estimation (Table 6): MogaNet variants yield at least 0.9 AP improvements for 256×192 input, e.g., +2.5 and +1.2 over Swin-T and PVTv2-B2 by MogaNet-S.
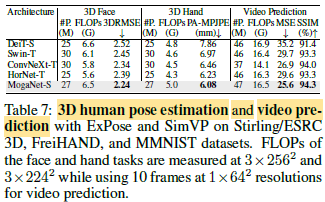
MogaNet-S shows the lowest errors compared to Transformers and ConvNets.
2.3. Ablation and Analysis
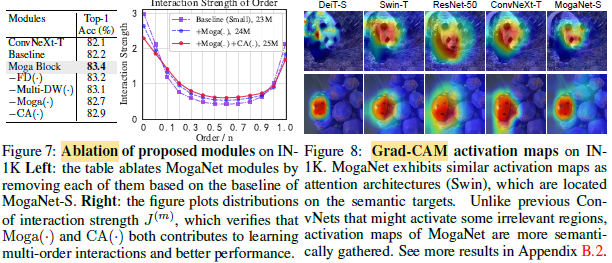
Figure 7: All proposed modules yield improvements with favorable costs.
