Review — MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
MViTv2, Improves MViTv1

MViTv2: Improved Multiscale Vision Transformers for Classification and Detection, MViTv2, by Facebook AI Research, UC Berkeley
2022 CVPR, Over 40 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Object Detection, Video Classification, Action Recognition
- Multiscale Vision Transformers (MViTv2) is proposed as a unified architecture for image and video classification, as well as object detection.
- An improved version of MViT / MViTv1 is presented that incorporates decomposed relative positional embeddings and residual pooling connections.
Outline
- MViTv2: Improved Pooling Attention
- MViTv2: Object Detection
- Image Classification Results
- Object Detection Results
- Ablation Studies
- Video Classification Results
1. MViTv2: Improved Pooling Attention

1.1. MViTv1: Pooling Attention
- Pooling Attention is introduced in MViTv1. For an input sequence, X, it applies linear projections WQ, WK, WV followed by pooling operators (P) to query, key and value tensors:

- The length is reduced after pooling. Then, the pooled self-attention:

- (Please feel free to read MViTv1 if interested.)
1.2. MViTv2: Improved Pooling Attention
1.2.1. Relative Positional Embeddings
- Relative positional embeddings, as in Shaw NAACL’18, are adopted, which only depend on the relative location distance between tokens into the pooled self-attention computation.

- where p(i) and p(j) denote the spatial (or spatiotemporal) position of element i and j. However, the number of possible embeddings Rp(i), p(j) scale in O(TWH), which can be expensive to compute.
- To reduce complexity, the distance computation is decomposed between element i and j along the spatiotemporal axes:

- where Rh, Rw, Rt are the positional embeddings along the height, width and temporal axes.
1.2.2. Residual Pooling Connections
- MViTv1 has larger strides on K and V tensors than the stride of the Q tensors.
- The residual pooling connection is added with the (pooled) Q tensor to increase information flow:
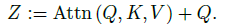
1.3. Model Variants
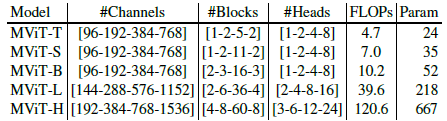
- Five variants (Tiny, Small, Base, Large and Huge) are designed for MViT by changing the base channel dimension, the number of blocks in each stage and the number of heads in the blocks.
2. MViTv2: Object Detection
2.1. FPN Framework

- MViT produces multiscale feature maps in four stages, and therefore naturally integrates into Feature Pyramid Networks (FPN) for object detection.
- With varied image sizes, positional embedding is interpolated.
2.2. Hybrid Window Attention (Hwin)
- Pooling attention: pools features by downsampling them via local aggregation, but keeps a global self-attention computation.
- Window attention: as in Swin Transformer, keeps the resolution of tensors but performs self-attention locally by dividing the input (patchified tokens) into non-overlapping windows.
- Hybrid Window Attention (Hwin): computes local attention within a window in all but the last blocks of the last three stages that feed into FPN. In this way, the input feature maps to FPN contain global information.
3. Image Classification Results

- Compared to MViTv1, the improved MViTv2 has better accuracy with fewer flops and parameters.
- MViTv2 outperforms other Transformers, including DeiT and Swin, especially when scaling up models.
Full crop testing can increase our MViTv2-L ↑ 384² from 86.0 to 86.3%, which is the highest accuracy on IN-1K to date.
4. Object Detection Results

(a) MViTv2 surpasses CNN (i.e. ResNet and ResNeXt) and Transformer backbones (e.g. Swin, ViL and MViTv1).
- e.g., MViTv2-B outperforms Swin-B by +2.5/+2.3 in APbox/APmask, with lower compute and smaller model size.
- When scaling up, deeper MViTv2-L improves over MViTv2-B.
(b) A longer training schedule with large-scale jitter, boosts the APbox to 55.8.
5. Ablation Studies

Left: Adding Swin or Hwin both can reduce the model complexity with slight performance decay. However, directly increasing the pooling stride (from 4 to 8) achieves the best accuracy/compute tradeoff.
Right: For MViTv2-S, directly increasing the pooling stride (from 4 to 8) achieves better accuracy/computation tradeoff than adding Swin.
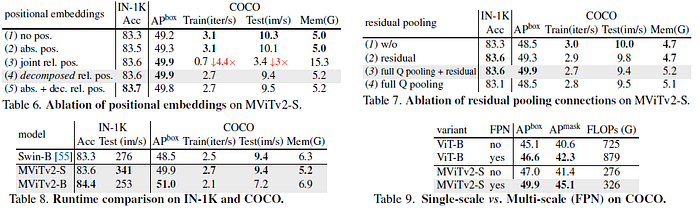
- Table 6: Relative positions can bring performance gain. Decomposed relative position embedding train 3.9× faster than joint relative position on COCO.
- Table 7: Using residual pooling and also adding Q pooling to all other layers (with stride=1) leads to a significant boost.
- Table 8: MViTv2-S surpasses Swin-B on both IN-1K (+0.3%) and COCO (+1.4%) while having a higher throughput (341 im/s vs. 276 im/s) on IN-1K and also trains faster, on COCO with less memory cost.
- Table 9: FPN significantly improves performance for both backbones while MViTv2-S is consistently better than ViT-B.
6. Video Classification Results

- For the temporal domain, a T×τ clip is sampled from the full-length video which contains T frames with a temporal stride of τ.
- Table 10: On K400, when training from scratch, MViTv2-S & B models produce 81.0% & 82.9% top-1 accuracy which is +2.6% & +2.7% higher than their MViTv1.
- Table 11: On K600, When training MViTv2-B, 32×3 from scratch and achieves 85.5% top-1 accuracy, which is better than the MViTv1 counterpart (+1.4%), and even better than other ViTs with IN-21K pre-training.
- The larger MViTv2-L 40×3 sets a new state-of-the-art at 87.9%.
- Table 12: On K700, MViTv2-L achieves 79.4% which greatly surpasses the previous best result by +7.1%.
- Table 13: On Something-Something-v2, MViTv2-S with 16 frames first improves over MViTv1 counterpart by a large gain (+3.5%). MViTv2-B boosts accuracy by 1.6% and achieves 72.1%. MViTv2-L achieves 73.3% top-1 accuracy.
- Table 14: Using either IN1K or IN21k pre-training boosts accuracy compared to training from scratch.
Reference
[2022 CVPR] [MViTv2]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
1.1. Image Classification
1989 … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer] [Sparse MLP] [MViTv2]
1.4. Object Detection
2014 … 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] 2022 [PVTv2] [YOLOv7] [Pix2Seq] [MViTv2]
1.10. Video Classification / Action Recognition
2014 … 2019 [VideoBERT] [Moments in Time] 2021 [MViT / MViTv1] 2022 [MViTv2]
