Review — Augment Your Batch: Improving Generalization Through Instance Repetition
Batch Augmentation (BA), Augments Samples within the Batch
Augment Your Batch: Improving Generalization Through Instance Repetition, Batch Augmentation (BA), by ETH Zurich, and Technion
2020 CVPR, Over 50 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Data Augmentation, Machine Translation, Dropout
- Batch Augmentation is proposed: replicating instances of samples within the same batch with different data augmentations.
- Batch augmentation reduces the number of necessary SGD updates to achieve the same accuracy.
Outline
- Batch Augmentation (BA)
- Experimental Results
1. Batch Augmentation (BA)
1.1. Vanilla SGD Without BA
- Consider a model with a loss function ℓ(w, xn, yn) where {xn, yn} where n is from 1 to N, is a dataset of N data sample-target pairs, where xn ∈ X and T: X →X is some data augmentation transformation applied to each example, e.g., a random crop of an image.
- The common training procedure for each batch consists of the following update rule (here using vanilla SGD with a learning-rate η and batch size of B, for simplicity):

- where k(t) is sampled from [N/B]={1, …, N/B}, B(t) is the set of samples in batch t.
1.2. SGD with BA
- BA suggests to introduce M multiple instances of the same input sample by applying the transformation Ti, here denoted by subscript i ∈ [M] to denote the difference of each transformation.
- The learning rule is modified as follows:

- where a batch of M·B composed of B samples is augmented by M different transformations.
- This updated rule can be computed either by evaluating on the whole M·B batch or by accumulating M instances of the original gradient computation.
- Using large batch updates as part of batch augmentations does not change the number of SGD iterations that are performed per epoch.
1.3. BA Applied on Intermediate Layers
2. Experimental Results
2.1. Study of M on CIFAR

- The above figure shows an improved validation convergence speed (in terms of epochs), with a significant reduction in final validation classification error.
This trend largely continues to improve as M is increased, consistent with the expectation.
- In the experiment, a ResNet44 with Cutout is trained on Cifar10. 94.15% accuracy is achieved in only 23 epochs for ResNet44, whereas the baseline achieved 93.07% with over four times the number of iterations (100 epochs).
- For AmoebaNet with M=12, 94.46% validation accuracy is reached after 14 epochs without any modification to the LR schedule.
2.2. SOTA Comparison
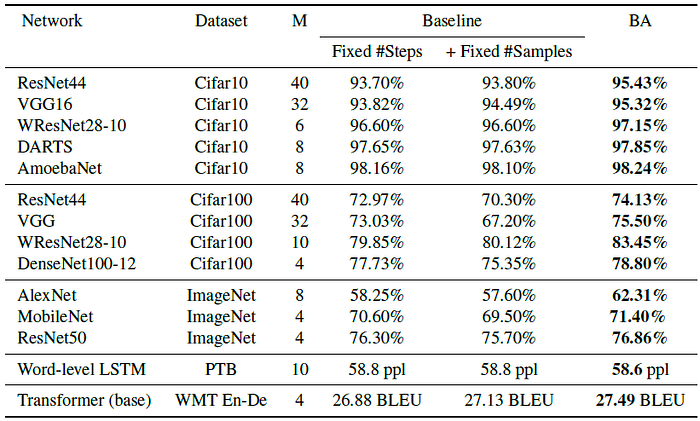
- Two baselines: (1) “Fixed #Steps” — original regime with same number of training steps as BA (2) “Fixed #Samples” — where in addition, the same number of samples as BA were observed (using M·B batch size).
- BA using Dropout is applied on language and machine translation task: PTB and WMT En-De.
Performance is improved with the use of BA on CIFAR, ImageNet, PTB and WMT En-De.
By comparing with “Fixed #Steps” and “Fixed #Samples”, BA augments the samples within the batch is essential to improve the performance
Reference
[2020 CVPR] [Batch Augment, BA]
Augment Your Batch: Improving Generalization Through Instance Repetition
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL] [ciFAIR] [ResNeSt] [Batch Augment, BA]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS]
Machine Translation
2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE] [GMNMT] 2019 [AdaNorm] 2020 [Batch Augment, BA] 2021 [ResMLP]
